

Dejando todo eso que hace el médico en el consultorio para revisarnos cuando le decimos que nos duele acá (la semiología), el resto de las prácticas en medicina cambiaron radicalmente en los últimos dos siglos, principalmente gracias a los avances tecnológicos. Hoy la traumatología tiene a su disposición un montón de instrumentos y procedimientos de diagnóstico basados en ecografias, radiografias, resonancias magnéticas y demás aparatos impensables en tiempos pasados; la cardiología se vale de electrogramas, hemogramas y diferentes análisis de sangre para entender y diagnosticar diferentes patologías; y así ocurre con muchas sino todas las ramas de la salud. La lista de ejemplos es interminable. Sin embargo, relegada a un costadito, la psiquiatría parece haberse perdido las últimas actualizaciones. ¿Puede esto deberse a que su objeto de estudio −la mente− es algo abstracto e intangible? Tal vez, pero eso se parece más a una excusa que una respuesta satisfactoria.
La realidad es que en los últimos años se gestó una nueva área en la psiquiatría que busca, con esfuerzo colectivo interdisciplinario, describir patologías conocidas usando modelos: sistemas matemáticos/computacionales que permiten entender y describir fenómenos. La llamaron, en un arrojo de creatividad, psiquiatría computacional.
Ahora ¿por qué sería útil darle herramientas computacionales a un psiquiatra?
El diagnóstico psiquiátrico, a diferencia de otras áreas de la medicina, se basa fuertemente en datos e interpretaciones altamente subjetivos: los discursos del paciente, las decisiones que toma y la forma en la que narra esas decisiones, reportes y descripciones del comportamiento por parte de familiares o amigos y, por supuesto, la subjetividad del médico al evaluar al sujeto íntegramente considerando diferentes fuentes de información (factores ambientales, datos demográficos, predisposiciones genéticas, entre otras). La psiquiatría tradicional no puede eludir este tipo de material; pero para mitigar la parte más subjetiva de estas prácticas, los problemas y la complejidad de lidiar con un objeto de estudio tan inasible, la clínica psiquiátrica cuenta con diferentes mecanismos basados en tests y formularios estandarizados que le permiten describir protocolos mucho más informativos, rigurosos, comparables y reproducibles que un simple ‘Che ¿cómo estás?’. Entonces, ahora sí la respuesta a por qué sería útil dotar a la psiquiatría también con herramientas computacionales resulta bastante más evidente: para bajar la cuota de apreciaciones subjetivas durante el relevamiento de diferentes aspectos de las enfermedades.
Cómo entrenar a tu algoritmo
Los primeros coqueteos entre estas dos áreas en principio tan distantes −la computación y la psiquiatría− se dieron en la década de los ‘80. Los modelos computacionales usados eran sistemas en los que se le ofrecían al paciente preguntas definidas por los expertos a través de una computadora y las respuestas eran registradas automáticamente. Luego se les aplicaba un sistema de reglas estático del estilo ‘si el paciente responde A en la pregunta 1 y B en la pregunta 2, entonces significa tal cosa’. Los sucesivos modelos fueron avanzando en prácticas cada vez más sofisticadas y los programas empezaron a chequear las respuestas en test psicológicos estandarizados. Esto permitió abstraer y comparar los patrones de síntomas en cada cuadro de cada paciente.

Ejemplo de modelo computacional. #arte #diseño #hashtag
Muchos de estos modelos sofisticados se enmarcan dentro del paradigma que las ciencias de la computación definen como machine learning (o aprendizaje automático): una subárea de la inteligencia artificial que tiene como objetivo crear modelos computacionales específicos para diferentes tareas. La particularidad de este paradigma es que el algoritmo ‘aprende’ a partir de la interacción con diferentes experiencias o muestras, con el objetivo de mejorar su desempeño en una tarea en particular.
Por ejemplo, supongamos que queremos hacer un programa que al darle una foto determine si se trata de un perro o de un gato. Para esto, antes de hacer que responda se ‘entrena’ al programa, dándole ejemplos de fotos y diciéndole ‘esto es un perro‘ o ‘esto es un gato‘. Tras recibir estos ejemplos de entrenamiento, el algoritmo ‘intenta’ capturar la noción de perro y de gato con alguna representación matemática, típicamente inentendible por un ser humano. Si lo logra, el algoritmo queda más que listo para resolver si una foto corresponde a un perro o a un gato.

Ahora te quiero ver, programita.
La discusión sobre si este tipo de comportamiento expresado por el programa es o no es inteligente se ha cobrado la vida de varias personas en duelos nerds (?), pero sin duda hay de las dos opiniones. Lo cierto es que, inteligentes o no, los programas alcanzan resultados sobre-humanos en muchas tareas de aprendizaje automático, sobre todo cuando el objeto a modelar son imágenes. Es decir que alcanzan mejores resultados que nosotros, incluso en aquellas tareas en las cuales los humanos somos muy buenos pero no sabemos bien cómo lo hacemos. Porque, admitámoslo, no tenemos mucha idea de cómo hacemos exactamente para resolver si en la foto hay un gato o un perro, pero lo hacemos excelentemente bien a partir de los primeros años de vida, a pesar de haber estado expuestos a muchísimos menos casos que los que un programa usa para entrenarse.
Lo bueno de este tipo de tecnologías −sin ánimo de desmerecer a quienes encuentren significativamente importante desarrollar algoritmos que puedan distinguir perros de gatos−, es que no sólo se puede entrenar máquinas para que reconozcan animales en imágenes, sino que también podemos entrenarlas para ser usadas en psiquiatría.
En el área de psiquiatría computacional, uno de los primeros casos de aplicación de modelos de aprendizaje automático fue en pacientes depresivos o bipolares en fase depresiva (estas patologías tienen como características principales depresión del estado de ánimo, falta de interés o placer en actividades que antes lo generaban, pérdida de peso, trastornos de sueño y fatiga, entre otros). Los modelos usados en un principio eran muy simples: se estudiaba la calidad de las emociones expresadas por los sujetos (positivas y negativas) y su intensidad, los términos referidos a los aspectos sociales, etc. Toda esta información se metía en un modelo que permitiera inferir cuál era el perfil de los sujetos depresivos. Es decir, en vez de obtener los patrones que definen a un perro, este modelo había sido entrenado para inferir las características subyacentes de un discurso depresivo.
A partir de esta experiencia, junto a un grupo de colaboradores empezamos a pensar que quizás era posible extraer información de otro tipo de discursos; por ejemplo, en pacientes esquizofrénicos, intentando capturar los diferentes fenómenos que caracterizan y definen este cuadro. El ‘Manual diagnóstico y estadístico de los trastornos mentales’ (DSM), describe el espectro esquizofrénico y otros desórdenes psicóticos con varias y diferentes características. Algunas están relacionadas a alucinaciones, otras a delirios. Pero existe una cualidad particularmente útil para estudiar computacionalmente la esquizofrenia: el discurso desorganizado. Según describe el DSM- V, el discurso desorganizado es incoherente, salta de un tema a otro o responde preguntas de una manera no relacionada con el disparador.
Usando herramientas de procesamiento del lenguaje natural (la subárea de la inteligencia artificial encargada de lidiar con los lenguajes humanos), publicamos en 2015 un trabajo que describía un algoritmo capaz de medir esta alteración presente en pacientes esquizofrénicos. La base del algoritmo radicaba en interpretar lo más literalmente posible la noción descrita de incoherencia: ‘el individuo salta de un tema a otro’. Pero necesitábamos alguna forma matemática de representar las palabras, ya que la matemática es el lenguaje de las computadoras. Para eso usamos una herramienta que traduce del mundo de las palabras al mundo de las coordenadas: los word embeddings.
Dónde quedan las palabras
Para entender qué es el mundo de las coordenadas podemos pensar en un ejemplo simple: las coordenadas GPS de Buenos Aires (34°34’ S, -58°28’ O) y de Montevideo (-34°54’, -56°09’), que se encuentran relativamente cerca en kilómetros, son ‘similares’. Por otro lado, si comparamos las coordenadas de Buenos Aires con las de Quito (0°10’, 78°28’) no son tan similares. Esto mismo se puede hacer con los word embeddings: si dos palabras están relacionadas semánticamente entre sí, en el mundo de las coordenadas estarán más cerca que dos palabras no relacionadas.
Veámoslo en un ejemplo. Supongamos que tenemos las palabras manzana, pera, naranja, perro, gato, elefante, mesa, vaso, plato y mosca, y que nuestro modelo de word embedding ya está entrenado y sabe traducir las palabras a coordenadas de 2 dimensiones. Entonces, una posible traducción para este conjunto de palabras podría ser la siguiente:
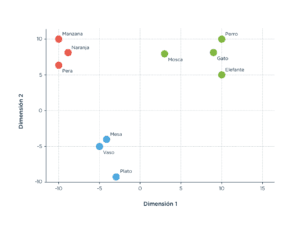
El modelo de word embedding ordenó las palabras del espacio de 2 dimensiones de una manera bastante interesante. Se ven agrupadas las frutas alrededor de las coordenadas (-10, -8), los animales cerca de la coordenada (10, 10) y el otro grupo de palabras alrededor del (-4, -5).
En el ejemplo anterior, las palabras fueron elegidas ‘a mano’ en función a tres categorías simples. Es interesante la manera en que el modelo las ordenó porque, oh casualidad, agrupó las coordenadas de las palabras en las mismas categorías semánticas que pensamos para armar el ejemplo (los animales por un lado, las frutas por otro, etc.). Vemos que palabra ‘mosca’ tiene coordenadas bastante particulares; si bien está cerca de las coordenadas de animales es, por lejos, la que más cerca está de las frutas. Si bien esto puede parecer extraño, tiene cierto sentido semántico. Las moscas y las frutas están cerca en el mundo que nos rodea. De alguna manera, esta relación semántica más débil que la relación de clase (animal o fruta) tiene que ser capturada por el método.
Hay muchos experimentos de este estilo en los que invitan a sujetos a ordenar conceptos, y suelen encontrar que varios de los words embeddings usados se asemejan a cómo lo hacemos las personas.
Ante todo, coherencia
Teniendo disponibles modelos de word embeddings que nos permiten viajar del mundo de las palabras al mundo de las coordenadas, en nuestro trabajo presentamos un algoritmo que permite ensayar una definición de ‘pensamiento desorganizado’. Lo llamamos ‘algoritmo de coherencia’ y funciona así: a partir del discurso transcrito de un paciente (por ejemplo, la respuesta a la pregunta ‘¿Qué hiciste el fin de semana?’), partimos el texto en frases. El plan era buscar cuán cerca estaba cada una de esas frases de la siguiente, usando los words embeddings. El problema era que podíamos traducir palabras a coordenadas (como hicimos en el ejemplo de recién) pero no frases a coordenadas. Entonces necesitábamos encontrar una representación de cada frase, y para eso probamos lo más simple que se nos ocurrió: reemplazamos cada palabra de una frase por sus coordenadas y luego tomamos la coordenada promedio. Así, sustituyendo cada palabra por su coordenada y luego promediando las coordenadas por frase, un texto que antes era una lista de frases ahora era una lista de coordenadas.
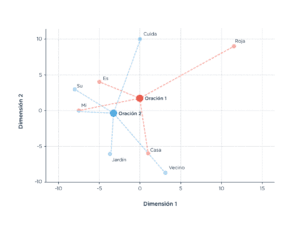
Una vez que obtuvimos una lista de coordenadas como representación del texto, nos propusimos medir la coherencia del texto en dos niveles de profundidad: la coherencia de nivel 1, que describe cuán coherente es el texto si comparamos frases contiguas; y la de nivel 2, que busca evaluar la coherencia del texto de una manera más profunda, midiendo la coherencia ya no entre frases contiguas sino con una frase de distancia. Es decir, comparamos la primera frase con la tercera, la segunda con la cuarta, la tercera con la quinta, y así sucesivamente. De este modo, luego de correr el algoritmo, obtuvimos para cada texto dos tipos de datos diferentes (de nivel 1 y de nivel 2).
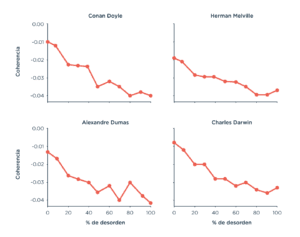
Pero no podíamos confiar en un algoritmo sin antes tener un control de que funcionara. ¿Cómo hicimos ese control? Agarramos obras clásicas de la literatura y mezclamos sus oraciones al azar; las analizamos con el algoritmo y dio como esperábamos: cuanto más mezclábamos las oraciones del texto original, más disminuía su coherencia.
Ahora sí, habiendo probado que el algoritmo andaba, era el momento de ensayarlo en pacientes con esquizofrenia. Invitamos a 20 pacientes y a 20 sujetos control a que nos contaran (de forma individual) qué habían hecho el fin de semana, los grabamos y le arrojamos esas respuestas al algoritmo para medir el nivel de coherencia en ambos grupos. La hipótesis se confirmó: la coherencia media de los sujetos esquizofrénicos era más baja que la de los sujetos control.
A la cancha
Como veíamos que todo estaba funcionando, nos propusimos entrenar un algoritmo de clasificación que, a partir del análisis de un nuevo discurso, pudiera decir si la persona que lo produjo era una persona con esquizofrenia. El resultado fue impresionante: encontramos que podíamos clasificar una nueva muestra con probabilidad de acierto superior al 85%. Es decir, en este grupo chico y potencialmente no representativo de la patología, pudimos entrenar un algoritmo de machine learning que, tras ofrecerle nuevas muestras, le acertó a si el sujeto tenía o no esquizofrenia el 85% de las veces.
Pero queríamos probar algo más: nos preguntamos si podíamos encontrar evidencias de distorsión en la coherencia del discurso en pacientes ‘sanos’, o al menos no diagnosticados con esquizofrenia, pero que por diferentes factores fueran considerados de alto riesgo de generar un estado patológico psicótico en un mediano plazo. Para eso contamos con una muestra de 34 pacientes del hospital de la Universidad de Columbia (EEUU). Les hicimos un seguimiento durante dos años y medio y, en ese tiempo, a 5 de esos pacientes se les diagnosticó esquizofrenia. Entonces vimos una oportunidad: era el momento de ver si había alguna diferencia en el discurso de estos 5 pacientes respecto de cuando eran sanos. Si su forma de expresarse era distinta, no sólo estábamos en condiciones de identificar la patología, sino que también podíamos hacer predicciones en plazos de meses.
Midiendo los valores de coherencia en esos textos, más otras características de lenguaje, logramos entrenar otro modelo de machine learning. Un nuevo método que nos permitió clasificar muestras de pacientes de alto riesgo y predecir cuáles generarían la patología y cuáles no, con un 100% de efectividad. Pero como este experimento estaba hecho con poquitos sujetos, lo repetimos con 59 pacientes más. El resultado fue de nuevo espectacular: pudimos predecir el desenlace en esquizofrenia con un 83% de efectividad.
Claro que nuestros resultados no convierten a estos algoritmos automáticamente en una herramienta de diagnóstico, pero sí muestran que estas tecnologías podrían ser muy útiles para complementar la visión crítica de los médicos. Estos ejemplos y muchos más ilustran cómo la psiquiatría puede ser sumamente nutrida por herramientas de las ciencias de la computación.
En tiempos en los que escuchamos y leemos cada vez más acerca de cómo algunas de estas tecnologías son usadas para vendernos productos o candidatos, es importante no sólo estar atentos y prevenidos en ese sentido (y usar las propias ciencias de la computación para defendernos de esas manipulaciones), sino también conocer la potencia que estas herramientas podrían ofrecer a los profesionales de la salud a la hora de predecir y diagnosticar diferentes condiciones psiquiátricas.
Bonus track
En los experimentos que contamos, la parte más difícil sin duda fue tomar la muestra del paciente por varios motivos, desde burocráticos hasta éticos, técnicos, económicos, etc. Cuando en nuestro laboratorio empezamos a trabajar en estos temas, los medicos grababan a los pacientes con cassettes que luego alguien tenía que, con muchísimo trabajo, transcribir a mano (posta). Entonces, entre que diseñábamos un experimento hasta que teníamos las mediciones hechas, pasaba mucho tiempo. Para mejorar esto creamos una app que permite la toma de registro de entrevistas psiquiátricas/psicológicas y luego el análisis de la aplicación de diferentes algoritmos, entre ellos el de coherencia. Si sos psicólogo, psiquiatra o trabajás o estudiás en temas relacionados y querés usarla, está disponible gratuitamente en http://sigmind.liaa.dc.uba.ar. ¡Escribinos!