Hay dos grandes misterios. El primero de ellos es la conciencia. ¿Cómo nace un punto de vista a partir de la materia del cerebro? ¿Qué tienen de especial los cerebros para generar algo tan único como la conciencia? ¿Por qué cada uno de nosotros tiene un punto de vista diferente a los demás; por qué yo soy yo, qué me trajo a mi cerebro y no al de otra persona? Los neurocientíficos han perseguido el origen de la conciencia hasta acorralarlo en esos 300 milisegundos que median entre un estímulo y su reporte. La información ingresa al nudo y se pierde en sus idas y vueltas; por un instante, parece que el cerebro ha devorado un fragmento del mundo. Pero 300 milisegundos más tarde, la misma información reaparece, aunque ahora transmutada en conciencia. Eadem mutata resurgo: “Cambiante y permanente, vuelvo a surgir, siendo la misma”.
El otro misterio es el mismísimo universo. ¿Por qué existe algo y no la nada? Es decir, ¿por qué existe el universo, de dónde viene y a dónde va, dónde estaba y dónde estará? Los físicos han acorralado el origen del universo en los instantes posteriores al big bang, la explosión inicial que dio origen a todo lo que conocemos. Estos avances son impresionantes, más aún considerando que nuestra especie bajó de los árboles hace tan solo miles de años, y que no lo hizo para mirar las estrellas, sino para asegurar su supervivencia. Incluso lo que somos hoy es el resultado de procesos ciegos a nuestra necesidad de entender de dónde venimos y por qué existimos.
Es lógico que el origen del universo sea un misterio. ¿Cómo podría ser de otra forma? Los físicos no pueden retroceder en el tiempo y apuntar sus instrumentos al big bang. Tampoco pueden hacer experimentos sobre el origen del universo: sea lo que sea que haya pasado, pasó una sola vez, y los seres humanos no estábamos presentes para medirlo. Puede que las preguntas sobre el origen último de todas las cosas sigan siendo un misterio para siempre, simplemente porque nunca tendremos los datos necesarios para formular las respuestas.
Pero la conciencia es distinta. A diferencia del big bang, la conciencia ocurre todo el tiempo alrededor nuestro, dentro de cientos de cráneos que encontramos todos los días. Ocurre en tu cerebro y ocurre en mi cerebro, y todo el tiempo está relacionada con objetos que podemos medir y sobre los cuales podemos experimentar. Pero aun así, el misterio se resiste. La conciencia es un misterio final que se desenvuelve a simple vista.
Así de tristes eran nuestras vidas antes de las omnicajas. Pensábamos todas estas cosas sobre la conciencia y sus misterios, sin sospechar que un día admitiríamos, algo avergonzados, cuál era el origen último de todas nuestras dificultades: estábamos midiendo mucho, sí, pero no estábamos midiendo lo suficiente. Ahora vamos a pensar dos veces antes de rendirnos ante el próximo problema científico que nos parezca imposible de resolver (big bang, no te tenemos miedo).
La omnicaja ya está encendida y el sujeto experimental yace en su interior, mientras terabytes de datos son capturados y copiados al servidor del laboratorio a cada segundo. El sujeto habla, aprieta botones y pestañea, y ante cada comportamiento distinto las trazas de su actividad cerebral adquieren formas características. La cuestión de la conciencia está inexorablemente ligada a la siguiente pregunta: ¿quién es nuestro sujeto experimental? Sin duda, la respuesta a esta pregunta está oculta entre los terabytes de datos que genera constantemente la omnicaja. El problema es: ¿cómo podemos encontrarla?
Nuestro trabajo científico recién comienza. Habiendo recopilado una inmensa cantidad de datos valiosos, el verdadero desafío es transformar esos datos en conocimiento; por ejemplo, el tipo de conocimiento sobre el que podemos enseñar o escribir libros. Aun si todavía no somos capaces de formular una teoría abarcativa sobre la conciencia, deberíamos poder analizar los datos para encontrar las regularidades que representen una antesala a dicha teoría. Recordemos cómo la ley de gravitación universal de Newton surgió luego de la síntesis sistemática de información realizada por Kepler, quien procesó montañas de datos astronómicos hasta encontrar una regularidad común al movimiento de todos los planetas (sus trayectorias elípticas). Análogamente, esperamos encontrar regularidades en los datos sobre comportamiento y actividad cerebral que proporciona la omnicaja. Idealmente nos gustaría que esas regularidades permitan (a nosotros o bien a científicos de generaciones venideras) formular una teoría formal sobre la conciencia y su relación con el cerebro.
Este escenario es ideal, aunque no necesariamente plausible. Además, incluso si fuese posible, ¿necesitamos realmente una teoría sobre la conciencia? Podríamos transformar la información en otro tipo de conocimiento, el tipo de conocimiento que plasmamos en mapas. No tenemos teorías formales para orientarnos en el bosque y en el mar, ni tampoco para describir cómo las estrellas están salpicadas a través de la bóveda celeste. Y si bien tenemos una teoría para explicar los orígenes de la biodiversidad, no es suficiente para explicar en su totalidad los caprichosos rumbos que ha tomado la vida desde sus inicios. Quizás la conciencia humana tenga más que ver con estas situaciones que con el sistema solar y la gravitación universal. Hay motivos para creer que ese es el caso: tal como la geografía, los cielos y la vida, cada identidad personal es el resultado del azar combinado con procesos que siguen reglas bien definidas. Si la conciencia es un reflejo de cada identidad personal, entonces será muy difícil comprimir todo sobre la conciencia en unos pocos axiomas. Una parte se resistirá a esta compresión, como sucede en todo sistema donde el estado actual de las cosas depende de la totalidad de su historia.
Ambos proyectos comienzan de la misma forma: identificando regularidades en los resultados proporcionados por una omnicaja. Ya sea en forma de teoría o como un conjunto de mapas, el porqué de la conciencia debe ser comunicable y entendible; debe ser posible interpretarlo (y también malinterpretarlo), y debe ser posible enseñarlo.
El desafío, entonces, es encontrar una forma de representar los datos de la omnicaja de forma más eficiente y sucinta. Buscamos comprimir los datos, descubriendo y explorando sus regularidades. Pero esta compresión únicamente es útil si podemos usarla como punto de partida para recuperar la totalidad de los datos. Para esto sirven las teorías y los mapas: para comprimir (y luego descomprimir) los datos obtenidos de experimentos y exploraciones con la menor pérdida de información posible en el camino.
Para entender cómo hacer esto, buscamos inspiración en una familia de redes neuronales artificiales conocidas como autocodificadores. Consideremos el siguiente esquema, que representa un autocodificador:
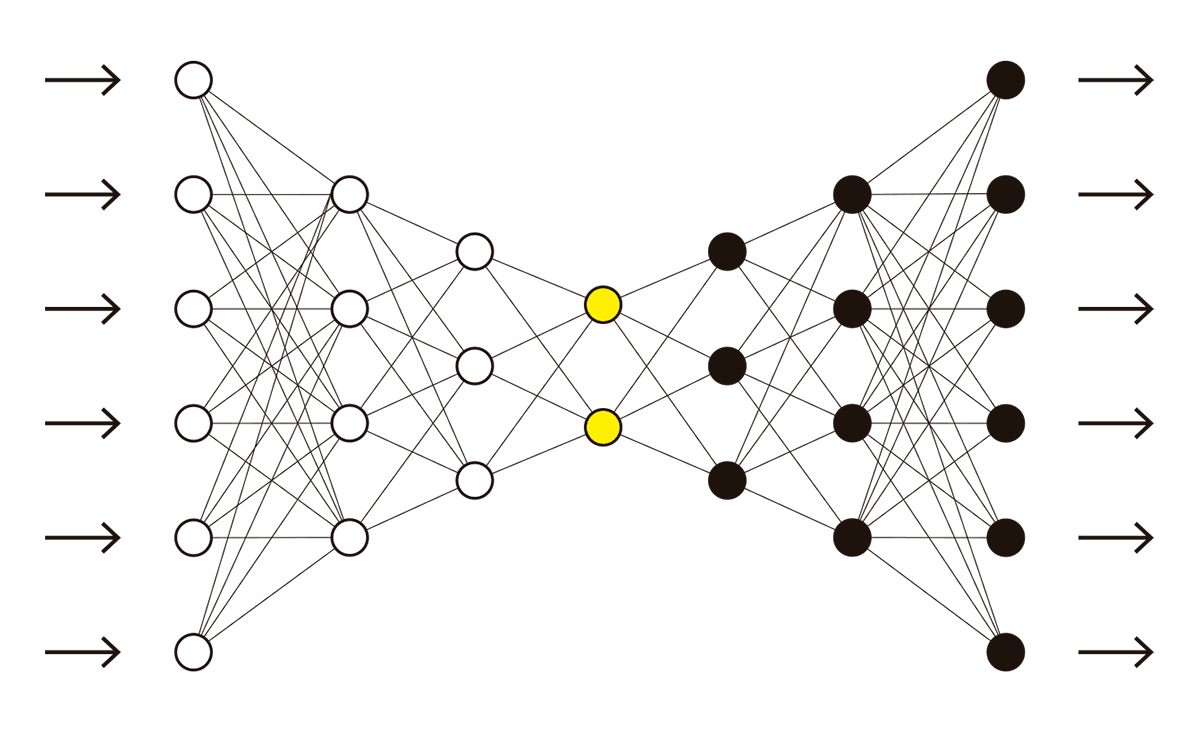
Este diagrama indica que seis unidades (círculos) blancas a la izquierda reciben seis datos numéricos distintos, y que esos datos se propagan (mediante alguna transformación matemática) a las cuatro unidades siguientes. Luego, ese proceso se repite para transformar los cuatro números de la segunda capa en los tres números de la tercera capa, hasta que finalmente se transforman en los dos números de la cuarta capa, los dos círculos en color amarillo. A partir de este momento, el proceso es idéntico, pero en la dirección contraria: los dos números se transforman en tres; luego, en cuatro; y, finalmente, en seis. En resumen, entran seis números al autocodificador y luego salen otros seis números. El autocodificador se basa en aprender qué transformaciones matemáticas deben aplicarse entre las capas para que los seis números de la entrada (blancos) sean lo más parecidos posible a los seis números de la salida (negros). Es decir, un autocodificador toma datos numéricos de entrada y se optimiza de forma intensiva para reproducir a la salida… ¡los mismos datos de la entrada!
¿Cuál es la gracia? El autocodificador, aparentemente, no está aprendiendo nada. Es como un loro que repite la información que le suministramos, un eco vacío de nuestros datos. Pero las apariencias engañan, porque en el proceso de transformar los seis números en sí mismos nuevamente, el autocodificador los hace pasar por el cuello de botella representado por las dos unidades amarillas de la capa intermedia. Esto quiere decir que podemos recuperar nuestros seis números únicamente a partir de dos, aquellos que están en el cuello de botella de la red. Así, un autocodificador aprende simultáneamente dos tareas: primero, cómo representar los seis datos numéricos utilizando únicamente dos números (compresión); luego, cómo recuperar los seis datos numéricos a partir de esos dos números (expansión).
Si los seis números que obtenemos luego de la expansión son muy diferentes a los originales, podemos concluir que fracasamos en representar los datos únicamente mediante dos números independientes. Por el contrario, si los datos expandidos son muy similares a los seis números de entrada, esto significa que logramos descubrir regularidades en los datos, la clase de regularidades que permiten tirar a la basura una buena parte de ellos y aun así obtener una representación reducida que permita recuperarlos en su totalidad.
Los autocodificadores están detrás de muchos algoritmos populares para la compresión de imagen, video y sonido. Por ejemplo, los valores numéricos correspondientes a la intensidad de cada píxel de una imagen podrían usarse para alimentar la primera capa de un autocodificador, el cual reduce sucesivamente la cantidad de números en las capas intermedias, hasta llegar a la mínima cantidad suficiente para recuperar una versión razonable de la imagen original. Luego, cada vez que queramos ver la imagen, lo único que hace falta es expandir esta representación (mediante la mitad derecha del autocodificador).
Existe una analogía entre este proceso y la forma en que los humanos aprendemos y sistematizamos el conocimiento: aprender es encontrar regularidades que nos permitan luego enseñar lo mismo que aprendimos con la menor pérdida posible de información en el proceso. En otras palabras: comprimir (aprender) y expandir (enseñar). La analogía entre el autocodificador y el método Feynman de aprendizaje (popularizado por Richard Feynman, el físico ganador del Premio Nobel) es casi exacta. El método consta de cuatro pasos sucesivos: comenzar a aprender un concepto, intentar enseñarlo, volver a aprender, mejorar la enseñanza. Esto es similar al proceso mediante el cual se optimizan los autocodificadores: comprimir los datos en la capa inicial, expandirlos y comparar con la capa final, volver a comprimirlos adaptando las transformaciones matemáticas entre capas, descomprimirlos y volver a compararlos con la capa final. Iterativamente, tanto el método Feynman como el autocodificador llevan al mismo resultado: una representación reducida de los datos (ya sea en el cerebro o en una red neuronal artificial) lista para ser expandida en todo momento, es decir, igual de útil que los datos originales, pero más económica en términos de espacio y recursos computacionales.
Este es el proceso que necesitamos aplicar a los datos generados por la omnicaja. El problema reside en la cantidad y complejidad de estos datos. Los métodos tradicionales para analizar los resultados de un experimento científico podrían colapsar cuando nos enfrentamos al volumen de información típico que generan las omnicajas: consideremos la dificultad de explorar (incluso de la forma más superficial) terabytes de datos comportamentales en diferentes formatos (audio, video, texto), junto con registros fisiológicos y neurofisiológicos de alta resolución espacial y temporal, y todo esto sin una teoría científica que nos guíe respecto de lo que estamos buscando. Si tan solo hubiese una forma automática de comprimir grandes volúmenes de datos sin tener que preocuparnos (al menos de momento) por los detalles…
Pero esto es precisamente lo que hacen los autocodificadores. ¿Por qué no conectamos la salida de datos de la omnicaja a un autocodificador y luego probamos con cuellos de botella cada vez más angostos, hasta que la salida del autocodificador deje de reproducir fielmente la entrada? Llegado ese punto, habremos determinado el grado máximo de compresibilidad en nuestros datos y, por lo tanto, habremos descubierto regularidades que contribuyen enormemente al conocimiento preteórico sobre la conciencia.
Ya presos del entusiasmo, proponemos que todas las omnicajas deberían comercializarse con un autocodificador incorporado, de forma tal que apretando un botón sea posible pasar del modo “datos crudos” (terabytes de información sin procesar) al modo “autocodificador” (una versión muy reducida de los datos que al mismo tiempo permita expandirlos para reconstruir los datos originales sin pérdida importante de información). Este invento recibe el nombre de auto-omnicaja, o –para mayor brevedad y a pedido del equipo de marketing– autocaja.
¿Puede que estemos exagerando con la utilidad de las autocajas? Volvamos por un momento al uso de autocodificadores para comprimir imágenes y video. Supongamos que partimos de una imagen de un cerebro dibujado a mano (como los que yo sé dibujar) y, además, que logramos comprimir la imagen de cientos de miles de píxeles a únicamente 63 números, que adecuadamente expandidos resultan en una reproducción razonable de la imagen inicial. ¿Qué esperamos encontrar si proyectamos esos 63 valores numéricos en una pantalla? Idealmente, quisiéramos que la respuesta a esta pregunta brinde información sobre el mecanismo que le permite al autocodificador comprimir y luego expandir exitosamente la imagen. Esperamos encontrar algo que esté relacionado con la imagen original, por ejemplo, si la dividimos en una grilla de 9 x 7 (=63), entonces quizás las 63 unidades de la representación comprimida puedan verse como una versión de baja resolución de la imagen original:
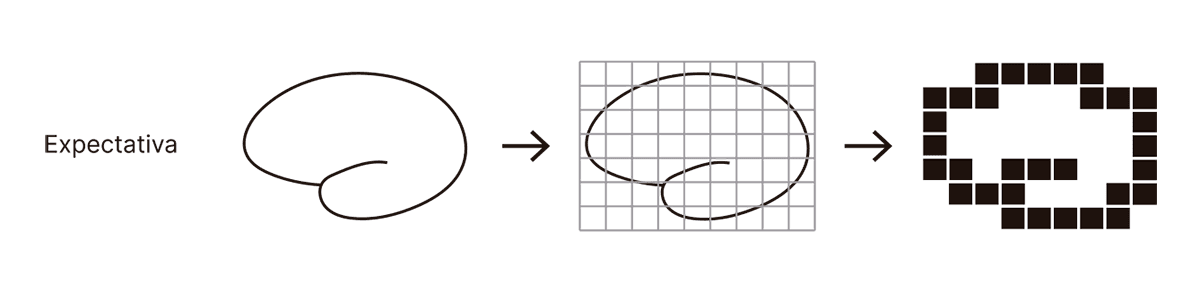
Si este fuese el caso, entonces la estrategia del autocodificador sería interpretable. La red neuronal, diríamos, está bajando la resolución de la imagen y guardando la transformación asociada, para luego invertirla y reconstruir la imagen original.
Pero esto no es lo que vamos a encontrar en la representación comprimida del autocodificador. De hecho, difícilmente encontremos algo que tenga sentido para la percepción visual humana, porque el autocodificador no está entrenado para que su representación comprimida de la imagen tenga sentido para un ser humano. El objetivo no es que entendamos por qué el autocodificador funciona; el objetivo es que funcione, y nadie dijo que la forma más eficiente de comprimir una imagen tiene que ser comprensible para un ser humano:
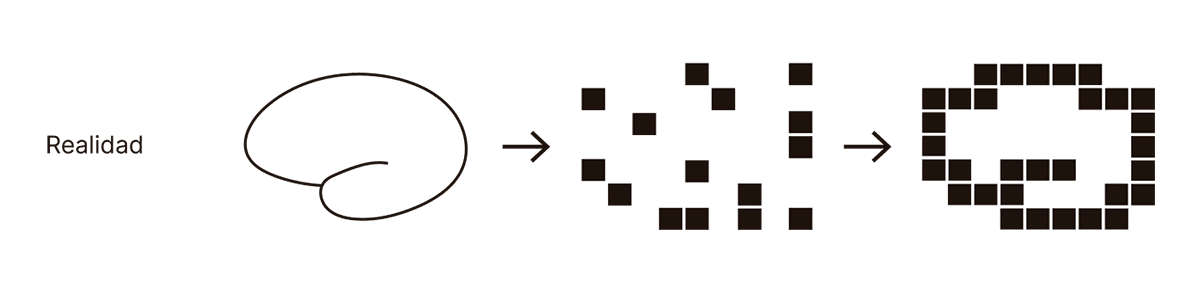
Todo vale siempre y cuando el autocodificador pueda expandir los 63 números para recuperar algo similar a la imagen de entrada. Lo mismo sucedería con las autocajas: los datos adquiridos durante el experimento serán representados de forma sucinta, sí, pero imposible de interpretar. Encontrar regularidades no es lo mismo que encontrar regularidades útiles, al menos desde la perspectiva de una científica o científico humano interesado en desarrollar una teoría que explique esas regularidades. Siguiendo con la analogía entre aprendizaje y autocodificación, esta es la tragedia que sufren algunos genios que son capaces de entender e interpretar grandes volúmenes de información, pero no pueden explicar por qué ni cómo, y que suelen ser desastrosos para la docencia (no es suficiente comprimir y expandir la información, hace falta también explicar por qué la compresión/expansión funciona).
Después de estas aclaraciones, ¿estaría dispuesto quien lee a invertir la considerable diferencia de precio que existe entre una autocaja y una omnicaja ordinaria? Si la respuesta es no, entonces espero convencerle de que, a pesar de sus posibles limitaciones, las autocajas representan un avance metodológico muy significativo, lo suficientemente útil e innovador como para justificar el desembolso adicional de dinero. Mi argumento no es únicamente teórico, sino que también se basa en el resultado de experimentos concretos realizados y publicados por mi laboratorio, algunos de los cuales pueden interpretarse como los primeros tímidos intentos de explotar rudimentarias autocajas.

Los Ángeles, 2028.1Si bien este párrafo y los siguientes son ficción, no están muy alejados de lo que pienso que puede pasar en un futuro próximo. Por suerte, vamos a poder comparar este futuro posible con el real, siempre que tengamos siete años de paciencia. Por primera vez, los Juegos Olímpicos deciden abandonar la subjetividad humana en el campo de la gimnasia artística para adoptar el puntaje automático mediante redes neuronales artificiales. Recordemos que, en el pasado, al terminar su rutina, cada gimnasta veía aparecer sus puntajes en un tablero electrónico. Los números reflejaban el criterio subjetivo de jueces humanos, seres falibles de carne y hueso, sujetos a errores, arbitrariedades, sesgos, envidias y rencores. Hasta que, en el año 2026, un trabajo publicado en la revista Gymnastics Today aportó la gota que rebalsó el vaso, el non plus ultra de la subjetividad humana en la gimnasia artística: un análisis computacional pormenorizado de todos los Juegos Olímpicos de la era moderna puso de manifiesto la existencia de sesgos de raza, género y nacionalidad en los jueces de la competencia. Por suerte, a lo largo de los años, las redes neuronales se fueron perfeccionando en la tarea de puntuar rutinas gimnásticas, al punto de constituir una alternativa más que viable llegados los Juegos Olímpicos de 2028 en Los Ángeles. Debido a que la arquitectura del sistema automático de puntaje está basada en los autocodificadores, todo el proceso algorítmico empieza a conocerse en los medios como “autopuntaje”.
El autopuntaje comprime miles y miles de videos de rutinas gimnásticas en una representación numérica muy reducida, imitando la forma en que los humanos asignan puntos a distintas dimensiones de la rutina. Esta asignación se basa en dos paneles independientes (E y D) que evalúan distintos aspectos. Cada uno de los paneles resume su evaluación en un puntaje y, finalmente, el gimnasta recibe el promedio de los puntajes de ambos paneles. El panel D asigna un puntaje basándose en la dificultad de la rutina intentada y en los elementos colectivos de la rutina (si los hubiese), mientras que el panel E evalúa la ejecución, composición y calidad artística. Parece tener sentido, entonces, implementar el autopuntaje mediante un autocodificador con dos unidades en su cuello de botella, cada una de las cuales representa la evaluación de los aspectos correspondientes a los paneles E y D.
Mediante una cuidadosa preparación de los datos, el equipo a cargo de implementar el sistema de autopuntaje se asegura de que la red neuronal artificial no aprenda a imitar los sesgos e imperfecciones de los jueces humanos. Por ejemplo, eliminan de los videos toda información que no corresponda al movimiento del cuerpo de los gimnastas (incluyendo información que permita identificar la etnia y la nacionalidad de los participantes, o incluso algunos sesgos menos discutidos, como qué tan atractiva es la persona). Luego, alimentan distintos autocodificadores con esta información y descubren que incluso para recuperar únicamente la información relacionada con el movimiento de los gimnastas, hacen falta decenas y decenas de números. Este descubrimiento evidencia la imperfección de los criterios subjetivos humanos: ¿cómo es posible que dos números hayan sido suficientes para los jueces humanos, cuando en realidad es imposible para el autocodificador expandir fielmente los datos a partir de una representación bidimensional de ellos? Cada vez hay menos dudas de que en Los Ángeles 2028 el autopuntaje dará lugar a la competencia más justa en la historia de la gimnasia artística.
Es entonces cuando surge un problema: a diferencia del puntaje otorgado por jueces humanos, nadie es capaz de entender qué significan los números con los que el autocodificador representa cada rutina artística. Por ejemplo, no es posible determinar cuáles de las dimensiones indican el puntaje de la rutina, la perfección técnica o la sensibilidad artística, incluso parece imposible determinar si esos son factores tenidos en cuenta por el autocodificador. Pero hay algo todavía peor: el conjunto reducido de números que comprimen las rutinas no es interpretable en términos ordinales, es decir, no es claro que menores valores indiquen peor desempeño y viceversa. Para los jueces humanos, las calificaciones se encuentran entre 1 (peor desempeño posible) y 10 (mejor desempeño posible). Pero los números que constituyen el autopuntaje no parecen estar ordenados, ni siquiera es claro, entonces, que su promedio tenga utilidad para rankear a los participantes de la competencia. El equipo a cargo del autopuntaje considera que estas limitaciones son catastróficas: el objetivo de eliminar la subjetividad y la arbitrariedad humana de la evaluación los condujo a desarrollar un sistema objetivo, pero al mismo tiempo imposible de interpretar. Ya cerca de reconocer su fracaso, y con pocos días por delante antes del comienzo de la competencia, el equipo está considerando seriamente volver a invitar a los jueces humanos, que ahora estarán visiblemente fastidiados por las acusaciones y la falta de confianza en sus criterios.
Hasta que de repente alguien sugiere una solución para este problema, una solución directa y sencilla que siempre estuvo al alcance de la mano. Si los números con los que el autocodificador comprime las rutinas no son interpretables, la solución es dejar de intentar interpretarlos. Pero, sin interpretación en términos de un puntaje, ¿cómo será posible rankear a los participantes? La respuesta es que no precisamos un sistema de referencia numérico absoluto para rankear rutinas de gimnasia: únicamente necesitamos comparar a los gimnastas entre sí, por ejemplo, introduciendo una medida de distancia (o, equivalentemente, de similitud) entre pares de rutinas. A mayor distancia, más disímiles son las rutinas, y podemos computar fácilmente una medida de distancia de la misma forma en que computamos la distancia entre puntos del espacio tridimensional, solo que en este caso el espacio tiene tantas dimensiones como números requeridos por el autocodificador para comprimir las rutinas. Lo único que resta hacer, entonces, es computar la distancia entre cada rutina de Los Ángeles 2028 y un conjunto de rutinas preseleccionadas consideradas ejemplares en relación con los aspectos de interés para los seres humanos. Por ejemplo, la rutina de piso ejecutada por Simone Biles en 2019 es considerada por muchísimos especialistas como la más difícil de la historia y, por lo tanto, su distancia respecto de cada rutina en esa categoría puede constituir un indicador objetivo del nivel de dificultad. O bien los dos 10 perfectos de Nadia Comăneci en los Juegos Olímpicos de Moscú 1980 pueden ser la vara respecto de la cual se mide la perfección técnica de la ejecución. En realidad, lo ideal sería computar la distancia promedio respecto de varias rutinas históricas consideradas ejemplares para reducir el efecto de la arbitrariedad implícita en elegir una única rutina.2Esto aliviaría también el potencial problema de reintroducir sesgos asociados con etnias, nacionalidades y géneros en el proceso de evaluación. Si bien es posible que este tipo de sesgos o arbitrariedades se manifiesten en la evaluación de algunas rutinas específicas, la posibilidad se atenúa cuando consideramos varias de las rutinas aclamadas unánimemente como las mejores de la historia.
Llegado este punto, podemos imaginar la siguiente objeción de los gimnastas: “¿Por qué en vez de evaluar mi rutina en cuanto a sus propios méritos, el autopuntaje la compara con rutinas pasadas de gimnastas que ni siquiera están participando de esta competencia?”. Pero este procedimiento no es específico del autopuntaje: es precisamente lo que hacen los seres humanos. Es difícil imaginar a una jueza humana que no aplique un procedimiento similar, es decir, que no determine el puntaje de al menos algunas categorías3El puntaje de algunas categorías es fácil de asignar algorítmicamente, incluso para un juez humano; por ejemplo, la dificultad de una rutina se determina en base a ciertas habilidades (skills) representadas en la rutina (tales como un salto mortal). Los jueces disponen de una tabla que codifica estas distintas habilidades y les asigna puntajes preestablecidos. mediante una comparación con su recuerdo de rutinas pasadas (de forma equivalente, que recalibre su vara de puntajes ante cada nueva rutina de la que es jueza). En otras palabras, incluso habiendo asimilado todo el conocimiento teórico sobre qué constituye una rutina perfecta, ¿alguien querría en las Olimpíadas a un juez que jamás haya presenciado un evento de gimnasia artística? Si la rutina perfecta ya fue realizada (si fue, digamos, la rutina de Simone Biles en 2019), entonces únicamente tenemos que estimar la distancia respecto de esta rutina para juzgar a los nuevos participantes; en cambio, si la rutina perfecta aún no fue realizada, cualquier juez humano va a guiar inevitablemente su evaluación en base a otras experiencias muy buenas que sí fueron realizadas.
La conclusión de esta historia sobre el futuro de la gimnasia artística es la siguiente: partiendo de suficientes datos, podemos asignar dimensiones numéricas a cada nuevo ejemplo, y aunque seamos incapaces de descifrar el significado de estas dimensiones, siempre que representen los datos de forma correcta podremos utilizarlas para introducir una idea de distancia entre los datos. Una vez que estamos armados con una idea de distancia, el problema se simplifica notablemente, porque trasladamos un montón de números de difícil interpretación a un único número con una interpretación inmediata: ¿qué tan parecidos son estos dos datos? Podemos comparar cada dato respecto de ejemplos especialmente informativos (por ejemplo, muy buenas rutinas en gimnasia artística). Más aún, al utilizar una distancia en el espacio de los datos, hacemos explícito nuestro punto de referencia (“la rutina de Simone Biles en 2019”) en vez de asumir la existencia de una hipotética referencia universal (“la rutina perfecta”). Es decir, cuando un juez humano puntúa una rutina con un 8 o un 9, ¿cuál es la escala que está utilizando? ¿Qué representan un 1, un 6, y un 10? En cambio, el autopuntaje es transparente en este sentido, porque todos sus juicios son relativos a rutinas pasadas concretas.
Estas conclusiones son especialmente importantes para entender la utilidad de las autocajas. Ahora queremos usarlas para enfrentar las siguientes preguntas: ¿qué significa la distancia entre los datos comprimidos a la salida de la autocaja? ¿Para qué sirve esta distancia en el estudio de la conciencia? ¿Existe algún ejemplo práctico, o son todas disquisiciones teóricas?

Empecemos por una pregunta más básica: ¿qué ganamos describiendo los datos mediante un conjunto reducido de números? Recordemos que limitar excesivamente a nuestros sujetos experimentales en el reporte de sus experiencias subjetivas es una mala idea. Las decisiones binarias (apretar o no un botón) o incluso las continuas (determinar el valor de un slider) no son suficientes, y por ese motivo se han propuesto herramientas alternativas para lograr una caracterización más detallada, desde escalas psicométricas (por ejemplo, Perceptual Awareness Scale o PAS) hasta descripciones en lenguaje natural (por ejemplo, la entrevista microfenomenológica). Naturalmente, los distintos científicos no están de acuerdo sobre las dimensiones necesarias para caracterizar una experiencia consciente (¿por qué lo estarían, siendo distintos?), lo cual complica considerablemente las cosas. Pero esta complicación surge porque insistimos en saber demasiado sobre la experiencia consciente, cuando en realidad podríamos avanzar con muchísimo menos conocimiento. Es decir, insistimos en conocer qué dimensiones caracterizan a una experiencia consciente, cuando en realidad podríamos empezar conociendo la similitud (o distancia) entre pares de experiencias conscientes.4La distancia proporciona estrictamente menos información que el conocimiento de las dimensiones mismas, porque se calcula a partir de ellas y ese cómputo no se puede revertir. Por ejemplo: podemos ubicar exactamente a alguien conociendo sus coordenadas (dadas por un par de latitud-longitud); en cambio, si solo sabemos que ese alguien está a 1 km de nuestra posición actual, entonces únicamente podemos afirmar que se encuentra dentro de una circunferencia de radio de 1 km alrededor nuestro. Pero aun siendo menos información, la distancia es útil para muchísimos fines prácticos (por ejemplo, para estimar cuánto tiempo me llevará viajar a ese determinado sitio). Y si tenemos suficientes datos, entonces podemos estimar esa distancia posponiendo la adopción de una posición teórica en particular, precisamente porque las dimensiones necesarias para calcularla tienen un origen pragmático, no teórico (es decir, vienen de responder la pregunta “¿Cuál es el mínimo conjunto de números que me permite reconstruir los datos originales con cierto grado preestablecido de fidelidad?”). Esto es análogo a optar por un mapa en vez de una teoría: buscamos orientarnos y navegar en el espacio de las posibles experiencias conscientes en vez explicar con detalle de dónde surgió ese espacio y por qué es como es.
Introducir una medida de distancia entre ejemplares de un conjunto es un primer paso fundamental. Es clave en cualquier intento sistemático de explorar el mundo natural, aun si luego se puede arribar a un conocimiento teórico del fenómeno lo suficientemente detallado como para volver obsoleta dicha distancia.
¿Qué podemos hacer armados de una medida de distancia? En primer lugar, podemos agrupar a los ejemplares de un conjunto, incluso si las fronteras que delimitan estos grupos son poco claras o difusas.5En la jerga del machine learning, este proceso de agrupamiento se conoce como clustering. Por ejemplo, pensemos en una descripción de distintos organismos vivos hecha durante un viaje de descubrimiento a través del mundo natural. ¿Qué tan parecidos son los distintos organismos entre sí? Habiendo respondido esta pregunta (esto es, habiendo introducido una distancia), podemos agrupar a los ejemplares de acuerdo a su similitud. Este agrupamiento sigue reglas precisas, es decir, podemos realizarlo de forma algorítmica mediante una secuencia de pasos bien definidos. Distintos algoritmos poseen diferentes fortalezas y limitaciones, pero todos tienen en común que se basan en una medida de distancia entre ejemplares. Un algoritmo particularmente útil es el llamado clustering jerárquico, que permite ubicar a los ejemplares dentro de grupos que, a la vez, poseen subgrupos de ejemplares similares entre sí, y así sucesivamente. El siguiente es un ejemplo de un agrupamiento jerárquico de un conjunto de animales basado en observaciones muy superficiales sobre su similitud:
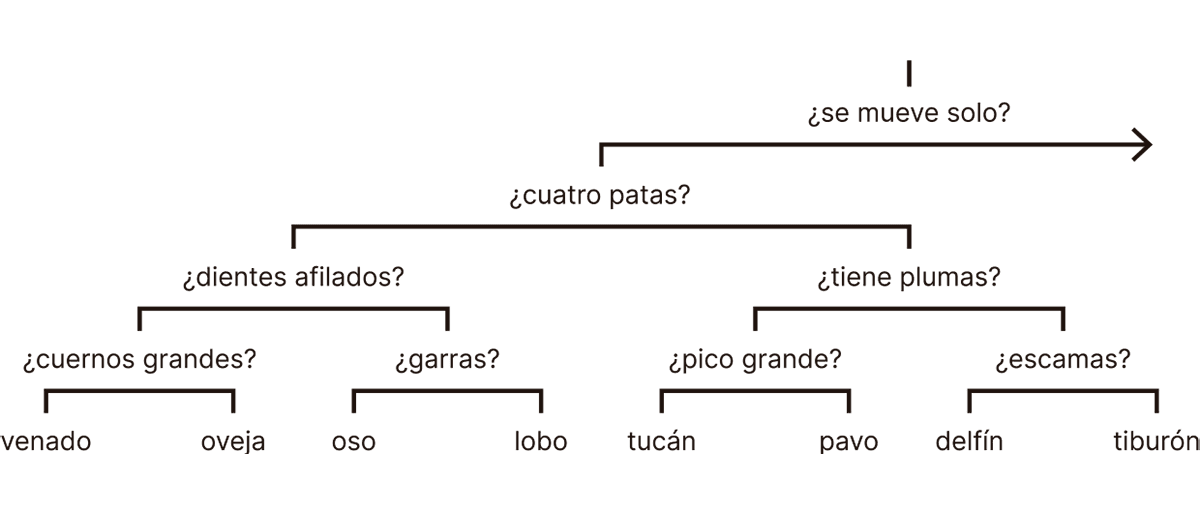
En este agrupamiento, venado, oveja, oso y lobo forman parte de un mismo grupo (tienen cuatro patas), que, a su vez, se divide en grupos de animales con dientes afilados (oso, lobo), y sin dientes afilados (venado, oveja). Este agrupamiento de los animales es sumamente ingenuo, pero eso se debe únicamente a que partimos de observaciones igualmente ingenuas sobre la similitud de los animales. Si hubiésemos incorporado mucha más información (incluyendo, por ejemplo, información sobre el comportamiento de los animales), habríamos descubierto que los delfines tienen más que ver con los osos y los lobos que con el tiburón.6Un desafío que enfrenta el naturalista es describir a los animales de forma tal que su clasificación sea lo más profunda posible. Si la clasificación es superficial o errada, entonces podría inducir intuiciones erróneas sobre el mecanismo que subyace a la variabilidad entre los ejemplares (mutación al azar y selección natural), y resultar en agrupamientos inconsistentes con aquellos obtenidos partiendo de un conocimiento teórico más sofisticado (como el que posibilita la secuenciación genética). Suponemos que nuestras autocajas son capaces de capturar una medida profunda de distancia entre ejemplares (las experiencias de nuestros sujetos). Precisamente por este motivo hicimos tanto énfasis en la capacidad de las omnicajas para capturar toda la información relevante para el estudio científico del problema. Lo importante es que una medida de distancia resulta automáticamente en una clasificación de los ejemplares, en la cual nosotros decidimos cuánto zoom queremos, es decir, cuánta especificidad.
En segundo lugar, una medida de distancia nos permite introducir una caracterización intuitiva de los datos, en el sentido de que siempre podemos identificar un ejemplar en base a su distancia con otros ejemplares que representan ciertos rasgos distintivos (tal como se hace en el proceso de autopuntaje en gimnasia artística). Así, podemos calcular el promedio de la distancia de un ejemplar determinado respecto de todos los animales con plumas, y decir que ese número representa la plumosidad del ejemplar. Aun si estas dimensiones no son las más adecuadas para describir a los ejemplares, por lo menos nos permiten explorar el conjunto de datos de forma intuitiva.
En tercer lugar, podemos entender la relación entre ejemplares independientemente de un ejemplar de referencia. Es verdad que podemos introducir esa dependencia si insistimos con analizar la distancia entre cada ejemplar y otros ejemplares preseleccionados (como en el cómputo de la plumosidad). Pero también es verdad que no tenemos por qué hacerlo, y podemos avanzar estudiando todos los pares de distancias entre ejemplares del conjunto sin enfocarnos en las distancias respecto de un ejemplar en particular.
Por último, supongamos que tenemos dos medidas de distancia definidas entre nuestros ejemplares; es decir, existen dos formas distintas en las cuales los ejemplares pueden ser similares o diferir. Cada distancia puede relacionarse a una propiedad distinta de los ejemplares, tan distinta que una comparación directa parece no tener sentido.
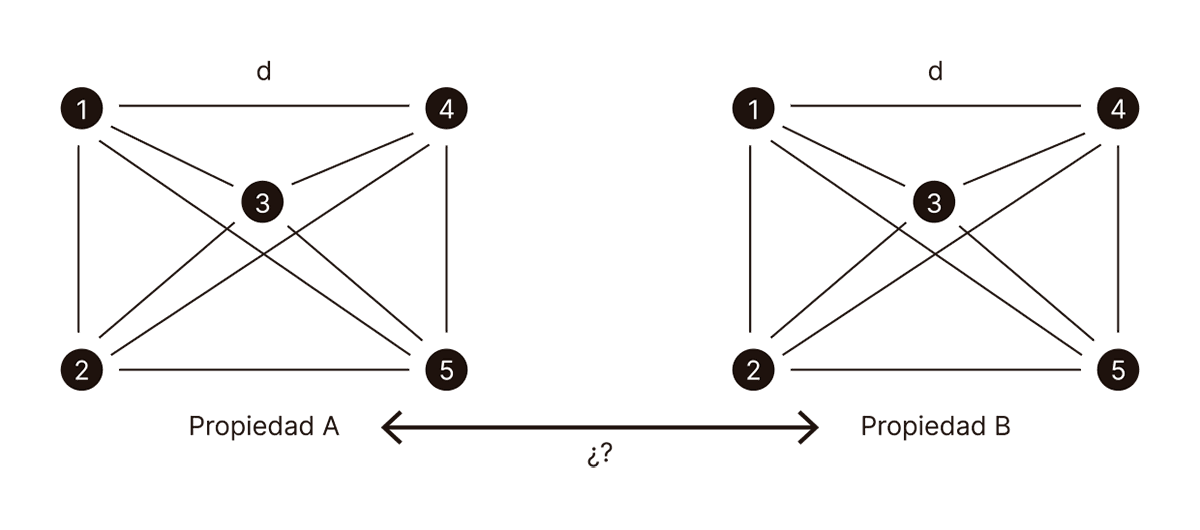
En este diagrama, las propiedades A y B caracterizan a cinco ejemplares distintos, y aunque tiene sentido comparar dos ejemplares en relación con su propiedad A (y lo mismo con la propiedad B), no es tan sencillo comparar directamente ambas propiedades entre sí. Por ejemplo, en el caso de los organismos vivos, las propiedades A y B podrían ser su aspecto físico y su código genético, respectivamente. El aspecto físico de un organismo y su genoma son cosas muy diferentes: el primero se captura mediante dibujos, fotos o descripciones, mientras que el segundo consta de una larga secuencia de letras que representan bases complementarias (A, G, C, T). ¿Cómo podríamos descubrir una relación entre ambas propiedades de los organismos vivos? ¿No estamos ante un típico caso de “comparar peras y manzanas”?
No si computamos todas las distancias entre pares de ejemplares en términos de ambas distancias, porque las distancias transforman pares de ejemplares en números, y los números siempre se pueden comparar entre sí, no importa cuál sea su origen.7Esta es la idea que hace funcionar al análisis de similitud de representaciones, un método propuesto hace más de una década por el neurocientífico cognitivo Nikolaus Kriegeskorte. En el año 2018, junto con mis estudiantes de doctorado Federico Zamberlan y Camila Sanz publicamos un trabajo donde redescubríamos esta idea en el contexto de relacionar reportes subjetivos de experiencias conscientes inducidas por drogas con las propiedades químicas y farmacológicas de las moléculas correspondientes. Entonces, podemos preguntarnos si distancias más elevadas en términos de la propiedad A son indicativas de distancias más elevadas en términos de la propiedad B y viceversa, como ilustra el siguiente dibujo:
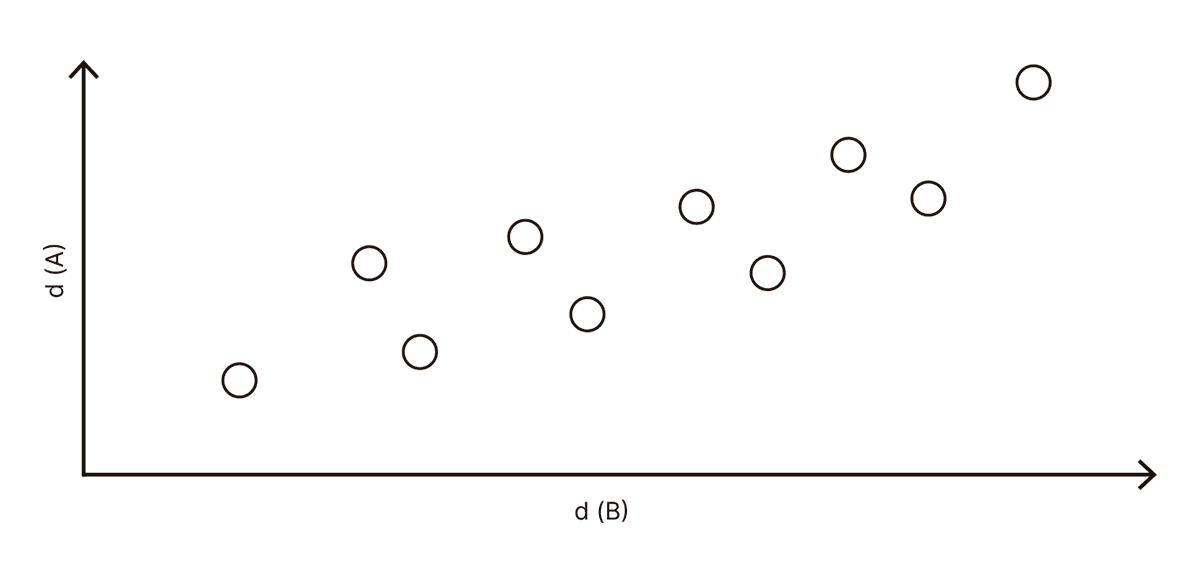
En este diagrama, cada punto representa un par de ejemplares. Para cada par, existen dos medidas de distancia: la distancia A (eje y) y la distancia B (eje x). Vemos que las distancias computadas en términos de la propiedad B (eje x) y en términos de la propiedad A (eje y) están claramente relacionadas: cuando una aumenta, la otra también. Esto quiere decir que el aspecto físico y el genoma no son independientes, porque los animales con mayor similitud física tienden a poseer más similitudes en partes de sus genomas, y viceversa.
Por supuesto, no todo el genoma de un organismo se relaciona directamente con su apariencia física. Por lo tanto, podemos refinar este procedimiento para averiguar qué porciones del genoma son las que se relacionan específicamente con el aspecto del organismo. Para eso computamos la distancia genética entre ejemplares, pero ahora utilizando únicamente una porción del genoma, y luego nos preguntamos si esa distancia está correlacionada con la distancia en cuanto al aspecto de los organismos. Si la respuesta es afirmativa, habremos encontrado evidencia que apoya que ese fragmento del genoma en particular juega un papel para determinar la apariencia del organismo. Repitiendo el proceso con muchos fragmentos distintos, podemos hacernos una idea cada vez más clara de la relación entre genes y aspecto físico.
Las autocajas nos permiten aplicar estos procedimientos al estudio de la conciencia. Podemos introducir una medida de distancia entre las experiencias de los sujetos al atravesar distintos paradigmas experimentales, tales como rivalidad binocular, backward masking, o el experimento del reporte parcial de Sperling. Esta medida de distancia podría, por ejemplo, permitirnos descubrir las distintas formas en que los sujetos reaccionan ante estímulos enmascarados al borde de la percepción consciente, no únicamente en relación con un reporte binario o continuo de “visto” vs. “no visto”, sino también mediante el uso de escalas psicométricas y relatos verbales sobre sus experiencias. En el caso del experimento del reporte parcial de Sperling, podríamos utilizar esta distancia entre experiencias para entender las variaciones posibles asociadas a la percepción de las letras en la matriz y a la simultaneidad (o falta de ella) entre el tono y la desaparición de las letras. Disponemos, además, de múltiples medidas de distancia en base al comportamiento y el reporte verbal luego de los experimentos, en base a rasgos individuales de cada sujeto, y también en base a sus registros de actividad cerebral. Armados con estas medidas de distancia, podemos buscar correlaciones entre distintos niveles descriptivos, que se corresponden a grandes rasgos con las perspectivas intencional, estadística, y de diseño, respectivamente. Estas correlaciones entre distancias pueden ser útiles para identificar qué características de la actividad cerebral se vinculan con cierto perfil de respuesta en sujetos con determinado perfil psicológico, lo que permite explorar sistemáticamente la relación entre individualidad y percepción consciente.8Muy posiblemente, nuestra hipótesis sobre percepción consciente y su relación con la imaginería visual sea equivocada o incompleta. Pero no importa, porque siguiendo este procedimiento podemos encontrar otros rasgos individuales que estén relacionados con los reportes de percepción consciente.
Este es un programa de investigación posible, aunque incipiente. El obstáculo principal es generar la cantidad de datos que se requieren para una caracterización tan exhaustiva de los sujetos y de sus experiencias. Las omnicajas son recursos discursivos que nos permiten, por un momento, conversar cuestiones de índole teórica sin tener que preocuparnos por los detalles prácticos de la implementación. Pero en última instancia tendremos que enfrentar el desafío experimental real que representa la materialización de las autocajas. Hoy aceptamos este reto, anticipando la colaboración voluntaria de muchísimas conciencias dispuestas a poner un pie dentro de la autocaja más cercana.

Llegó el momento de enfrentar una pregunta incómoda: ¿este libro trata realmente sobre la conciencia? Sin duda, trata sobre cosas como conciencia-A y conciencia-F, sobre la respuesta ante estímulos presentados durante pocos milisegundos, o bien ante distintas imágenes presentadas a cada ojo. La pregunta es... ¿cuánto tienen que ver todas estas cosas con la conciencia, en cuanto a su significado intuitivo y cotidiano? ¿Lo que aprendemos durante los experimentos discutidos hasta ahora aporta algo a nuestro entendimiento de la conciencia en general, o únicamente al entendimiento de la conciencia durante esos mismos experimentos?
Imaginemos que elegimos un habitante del planeta al azar y que nuestra tarea es explicarle en qué consiste nuestro objeto de estudio, es decir, qué queremos decir cuando decimos “conciencia”. Presumo que vamos a tener dificultades, algunas de ellas insuperables. Pensemos en nosotros mismos hace algunos años, antes de haber desarrollado un interés sobre la conciencia. ¿Cómo hubiéramos reaccionado ante una explicación acerca de “la rojez del color rojo”? ¿Es posible siquiera articular la distinción entre conciencia-F y conciencia-A sin páginas y páginas de definiciones y preliminares? ¿Todas las lenguas del planeta tienen una palabra para denotar “conciencia”, en el sentido de cómo se sienten las cosas en primera persona? Si la conciencia es tan íntima y omnipresente para los humanos, ¿qué sentido tiene nombrarla? Sospecho, además, que si retrocediéramos en el tiempo hasta la época de Descartes, por ejemplo, no sería tan fácil encontrar personas con un manejo sofisticado de estos conceptos, incluso dentro de ámbitos científicos y filosóficos. La conciencia nos es tan familiar que la dejamos a un lado: desarrollamos un lenguaje increíblemente específico y preciso para describir el mundo físico que sucede precisamente por fuera de la conciencia. En comparación, nuestro lenguaje introspectivo es muchísimo más pobre. Un habitante aleatorio del planeta difícilmente tenga más sofisticación al respecto que nosotros hace algunos años, o que un científico o filósofo del siglo XVIII.
Pero hay un aspecto de la conciencia que todos experimentamos íntimamente: la posibilidad de perderla y luego recuperarla. Pienso que tendríamos considerable éxito apelando a la intuición de conciencia como aquello que perdemos en el sueño profundo y recuperamos por la mañana al despertar. Esta intuición detrás de la conciencia es muy diferente a otras presentadas hasta ahora (conciencia-F, conciencia-A). No tiene que ver con contenidos específicos y su acceso a múltiples funciones cognitivas, sino con nuestra capacidad general para poder experimentar esos contenidos. La vigilia y el sueño profundo son ejemplos de estados de conciencia, extendidos en el tiempo y caracterizados por modificar globalmente nuestra experiencia subjetiva.9Es importante aclarar que los estados de conciencia incluyen también los estados de inconciencia (como el sueño). Es decir, identificamos los estados de conciencia por su modificación global y extendida en el tiempo de los contenidos de la conciencia, pero esta modificación también incluye su ausencia parcial o total. Son dos ejemplos dentro de una categoría amplia que incluye el sueño REM (la fase del sueño en la que típicamente soñamos), el efecto de fármacos sedativos o anestésicos, o, de forma general, el estado inducido por las drogas psicoactivas, entendidas como compuestos químicos capaces de modificar nuestra conciencia de formas idiosincráticas. Los estados de conciencia son intuitivos porque representan experiencias que vivimos cotidianamente. No necesitamos presentar estímulos durante fracciones de segundo en complejos paradigmas experimentales para motivar su definición, porque todos (independientemente de nuestro interés científico en la conciencia) transitamos varios de ellos en el transcurso de cada día.
A pesar de esta claridad intuitiva, existen dificultades considerables a la hora de definir exactamente qué constituye un estado de conciencia. Por ejemplo, si un estado de conciencia es una modificación global y extendida en el tiempo de los contenidos de la conciencia, ¿un orgasmo es un estado de conciencia? ¿Y la sensación de agudo dolor que sentimos al golpearnos un dedo contra un mueble? ¿Y qué pasa con un déjà vu, esa extraña sensación de estar pasando por una experiencia ya vivida? Podemos excluir o incluir algunos de estos estados trazando fronteras, pero estas fronteras son arbitrarias, y precisamente por eso es tan difícil alcanzar un consenso sobre qué constituye un estado de conciencia. ¿Y qué pasa con un déjà vu, esa extraña sensación de estar pasando por una experiencia ya vivida?
Otro problema en el estudio de los estados de conciencia es su clasificación usual en niveles. Esta clasificación se basa en la intensidad con la que se experimentan los contenidos conscientes durante cada estado. Por ejemplo, el sueño profundo presenta un nivel inferior de conciencia al estado de vigilia, porque la conciencia parece atenuarse o ausentarse, al menos por momentos. La idea de niveles de conciencia es análoga al concepto de temperatura en la física,10De hecho, varios científicos y filósofos plantean el desafío de construir un “termómetro” para la conciencia, entendido como un dispositivo capaz de cuantificar el nivel de conciencia con un único valor numérico. que permite ordenar los estados de un sistema a lo largo de un continuo unidimensional de valores. En el caso de la conciencia, este continuo unidimensional va desde su ausencia total hasta el estado de vigilia ordinaria que experimentamos todos los días.
La utilidad de este concepto desde un punto de vista clínico es innegable. Un cirujano necesita conocer la profundidad del estado anestésico inducido antes de iniciar la operación, y una de sus preocupaciones es que el paciente sea incapaz de experimentar dolor.1¿O de recordarlo? Es conocido que ciertas drogas anestésicas en realidad funcionan más como drogas amnésicas. El efecto amnésico es muy útil en intervenciones sencillas con anestesia local. Tal como aprendí durante mi operación por síndrome del túnel cubital, incluso la anestesia local es incapaz de suprimir el dolor generado por contacto directo o cercano con el nervio. Si no suprimimos el dolor, la segunda mejor cosa que podemos hacer es olvidarlo. Pero ¿qué pasa si se trata de una cirugía mayor, con cortes extensos de la musculatura y desplazamiento de huesos y articulaciones? Ciertas drogas anestésicas (que ya no están en uso, por suerte) ocasionalmente preservan la conciencia y los recuerdos de los pacientes, incluso durante este tipo de procedimientos altamente invasivos, lo que resulta en eventos muy traumáticos. Disponer de demasiados indicadores en esta situación podría resultar una distracción peligrosa. Encontramos situaciones análogas en neurología en cuanto a las fases del sueño. Los criterios estándar para clasificar el sueño humano introducen estados de progresiva profundidad en los cuales (asumimos) el nivel de conciencia es más y más bajo (el sueño REM es la excepción, como todos experimentamos cada vez que tenemos sueños vívidos). El uso de escalas unidimensionales es también fundamental en el proceso diagnóstico de trastornos de la conciencia, por ejemplo, el coma, el estado vegetativo y el estado de mínima conciencia. El diagnóstico y el pronóstico de los pacientes depende de múltiples factores (incluyendo la invaluable experiencia del médico) que luego se incorporan en el cómputo de un único índice numérico. Este índice influye en la decisión de discontinuar el soporte vital en aquellos casos que se consideran irrecuperables.12La mayoría de las personas tienen un concepto equivocado de lo que significa “desconectar al paciente”. Suelen imaginarse que se desconecta al paciente de la maquinaria que lo asiste con su respiración o circulación sanguínea, de forma tal que muere inmediatamente. Pero de acuerdo a las leyes vigentes en ciertas regiones del mundo (por ejemplo, en varios países de Europa), eso sería equivalente a asesinar al paciente. En vez de eso, entonces, se desconectan las vías que suministran nutrición y líquido: literalmente se lo deja morir de sed y hambre. La ausencia de experiencias subjetivas es el principal argumento para defender este criterio, que sería considerado, en otro contexto, como brutal e inhumano.
A pesar de su utilidad práctica, el concepto de niveles de conciencia es cuestionable desde un punto de vista teórico. ¿Se supone que la intensidad de la conciencia disminuye y aumenta de forma uniforme a medida que transitamos distintos niveles de conciencia? ¿Es cierto que podemos comparar el nivel de conciencia entre cualquier par de estados, por ejemplo, entre el estado de sueño ligero y el de un paciente neurológico en estado de mínima conciencia? La noción de niveles de conciencia se vuelve aún más difícil de sostener si intentamos aplicarla a estados de conciencia inducidos por drogas psicoactivas, por ejemplo, por compuestos psicodélicos tales como la LSD o la psilocibina. La mayoría de los científicos aceptan que estas drogas inducen estados de conciencia propiamente dichos, estados que duran varias horas y modifican de formas típicas y profundas la experiencia subjetiva del usuario. Pero ¿cuál es el nivel de conciencia? Es difícil sostener que los psicodélicos inducen un estado de conciencia expandida, en el sentido de que los contenidos de la conciencia se experimentan con mayor intensidad a la usual. Simplemente, esto no es lo que reportan los usuarios de drogas psicodélicas (vamos a dar más precisiones al respecto en unos pocos párrafos). Por último, recordemos cómo se siente el proceso de quedarse dormido: ¿es una disminución gradual de la conciencia, como si alguien estuviese bajando el brillo de una pantalla o el volumen de un parlante? ¿O más bien son saltos abruptos, apariciones y desapariciones, presencias y ausencias?
Una mañana otoñal de 2019 estaba saliendo de un hotel en Hamburgo cuando me crucé con un curioso dispositivo que los alemanes llaman Wetterstation (es decir, estación del clima), compuesto por tres diales que reportan la temperatura, la presión y la humedad. La Wetterstation fue para mí la gota que rebalsó el vaso. En ese momento, me pregunté: ¿necesitamos tres números para especificar el clima, pero uno solo alcanza para especificar el estado de conciencia? La idea de que existen niveles de conciencia me pareció de repente una burda simplificación, una forma de esconder nuestra ignorancia sobre el problema en pos de facilitar ciertas aplicaciones prácticas. No fui el único: tres años atrás, los filósofos Tim Bayne y Jakob Hohwy, junto con el médico neurólogo Adrian Owen, publicaron un trabajo titulado “¿Existen los niveles de conciencia?”. La respuesta fue un lapidario “no”. Pero si un único número no alcanza, entonces, ¿cuáles son las múltiples dimensiones necesarias para describir la conciencia? La falta de consenso al respecto es notable. A veces pareciera que únicamente resolviendo primero el problema de la conciencia vamos a ser luego capaces de dimensionarla adecuadamente (en realidad, por supuesto, el objetivo es utilizar estos indicadores para avanzar en nuestra explicación de la conciencia, y no al revés).
Pero aplicando las ideas desarrolladas en este capítulo empieza a ser claro que no es necesario encontrar esas dimensiones para ser capaces de decir muchas cosas útiles sobre los estados de conciencia. Es más, quizás ni siquiera necesitemos definir qué es exactamente un estado de conciencia. Lo que único que necesitamos es una autocaja bien calibrada, lista para recibir a sujetos experimentales transitando distintas experiencias, desde el gradual descenso hacia el sueño profundo hasta el efecto agudo inducido por ciertas drogas psicoactivas (siempre con la aprobación del comité de ética competente, por supuesto).
Un estado de conciencia no es más que una forma de agrupar estas experiencias en base a las dimensiones descubiertas por la autocaja.13Con esto operacionalizamos los estados de conciencia: en vez de decir qué son, damos un procedimiento para medirlos y encontrarlos a partir de los datos. Si el agrupamiento es jerárquico, resolvemos también el problema de qué tan específico puede ser un grupo de experiencias para que sigamos considerándolo un estado de conciencia (dolor de pie al golpearnos con un mueble vs. sueño profundo). Si nos interesan estados más específicos, llegaremos más profundo en el árbol jerárquico, mientras que si nos interesan estados globales amplios, alcanzaremos un nivel más superficial. De esta forma, evitamos el problema teórico de definir qué son los estados de conciencia y lo reemplazamos por una forma práctica de encontrarlos:14La biología enfrenta problemas similares cuando las fronteras entre grupos (especies) son difusas. Si un problema no puede resolverse teóricamente, entonces lo mejor que podemos hacer es resolverlo de forma pragmática, pero reproducible. agrupar algorítmicamente las dimensiones resultantes de poner a nuestro sujeto experimental en una autocaja.
La introducción de una distancia entre experiencias subjetivas resuelve otro problema, frecuentemente ignorado: si existe una variabilidad intrínseca en las conciencias humanas (incluso en ausencia de patologías neuropsiquiátricas), ¿cuál es el punto de referencia respecto del cual medimos los estados de conciencia? Es decir, si introducimos múltiples dimensiones que capturan el desvío respecto de un estado de referencia, ¿cuál es ese estado? La respuesta más frecuente es la vigilia ordinaria, pero la vigilia no tiene nada de ordinaria. Siempre que tengamos una medida de distancia, evitamos esta arbitrariedad: no necesitamos un punto de referencia mientras nos limitemos a computar la distancia entre pares de estados. La situación es análoga a la que imaginamos para los Juegos Olímpicos de Los Ángeles 2028: si queremos entender y evaluar una rutina, dado que no existe un criterio absoluto de evaluación, tenemos que compararla con otras rutinas muy conocidas que consideremos ejemplares. De la misma manera, si queremos entender un estado de conciencia, podemos compararlo con otros estados más estudiados y analizar las distancias resultantes.
Esta idea también está detrás de una gran revolución en nuestro entendimiento de la física. Uno de los mayores interrogantes de la física del siglo XIX era el siguiente: ¿desde qué punto de vista son válidas las ecuaciones que describen el universo? El problema era que las ecuaciones de Newton solo parecían ser válidas desde un único punto de vista privilegiado. Eso molestaba a quienes creían que las leyes de la naturaleza no deberían depender de dónde se encuentra parado quien las aplica. Albert Einstein estaba dentro de este grupo de científicos: su teoría especial de la relatividad conduce a formular leyes de la naturaleza expresadas únicamente en términos de distancias. Las coordenadas de puntos en el espacio dependen del sistema de referencia, pero la distancia entre dichos puntos es siempre la misma, no importa desde dónde se los esté mirando. Por eso, las leyes de la física así formuladas son invariantes (es decir, no cambian) ante los cambios de coordenadas implícitos en la adopción de distintos puntos de vista.
Llegamos, entonces, a tres alternativas para representar estados de conciencia:
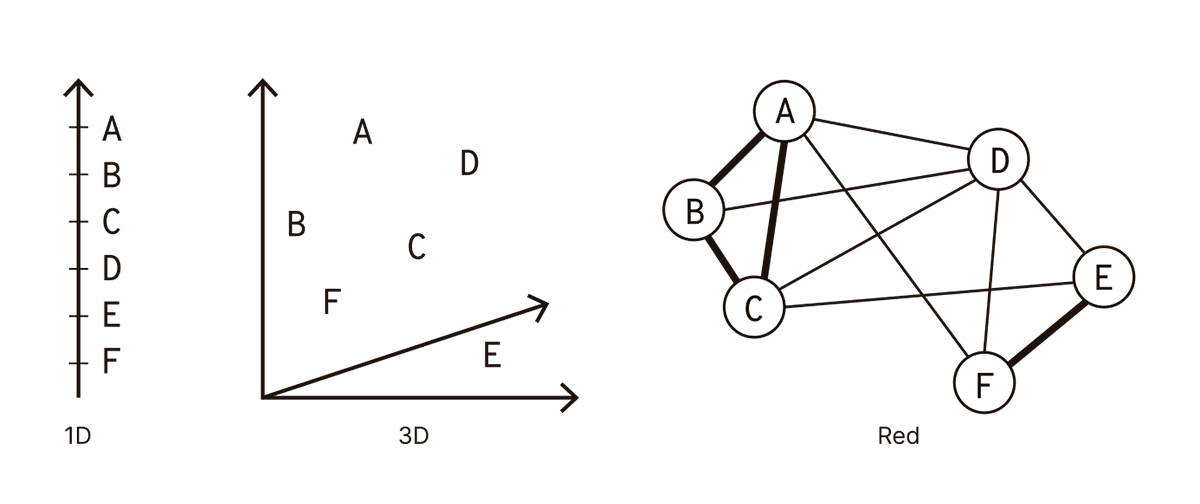
En el extremo izquierdo, los estados están representados unidimensionalmente (1D) en términos de niveles, como si se tratase de la temperatura en un termómetro. De acuerdo con esta representación, el estado A es “más consciente” que el estado B, que, a su vez, es “más consciente” que el estado C, y así sucesivamente. Si ocurriese que dos estados no son claramente comparables (por ejemplo, si el estado C corresponde al sueño REM, y el D, a un estado de delirio causado por fiebre muy alta), entonces tendremos que forzar la comparación al ubicarlos en una misma escala.
En el centro, encontramos una representación más sofisticada, basada en este caso en tres dimensiones (3D) que caracterizan a cada estado de conciencia. Las dimensiones podrían estar relacionadas con el contenido (mayor o menor intensidad de percepción visual, auditiva o táctil), o a las funciones cognitivas (mayor o menor control sobre procesos atencionales, o sobre la capacidad de automonitorear los propios procesos cognitivos). El problema difícil es determinar estas dimensiones y encontrar una solución consensuada que sirva para describir un amplio rango de estados de conciencia. Este problema permanece aún abierto.
Por último, el gráfico a la derecha del diagrama muestra cómo podemos avanzar computando la distancia entre los estados en base a dimensiones definidas pragmáticamente (por ejemplo, las dimensiones necesarias para reconstruir los datos con la mayor fidelidad posible usando un autocodificador). En ese caso, la representación correcta es en forma de una red o grafo. Los estados ya no están ubicados en un espacio con una cierta cantidad de dimensiones, sino de forma arbitraria sobre un plano. Únicamente las relaciones entre ellos importan (por ejemplo, su distancia relativa). En esta red, los estados se encuentran unidos por conexiones cuyo grosor indica el grado de relación (en este caso, a mayor grosor, menor distancia). Esta es la clase de representación que vamos a buscar y explorar a partir de datos empíricos en la próxima sección.

Las omni- y autocajas son un recurso que nos permite explorar las implicaciones de la perspectiva estadística en el estudio de la conciencia. Recordemos que la motivación detrás de esta nueva perspectiva es entender con la mayor profundidad posible qué quiere decir un sujeto sobre su estado de conciencia puesto en el contexto de toda la información relevante que podamos acumular sobre él o ella. Pero podemos pensarlo de una manera diferente, en la cual no adoptamos la perspectiva estadística respecto de un sujeto particular, sino respecto de un estado de conciencia. En este caso, el objetivo pasa a ser caracterizar exhaustivamente la mayor cantidad posible de información sobre dicho estado de conciencia, de forma transversal a muchos sujetos distintos. Cuando uno tiene muchos sujetos distintos también tiene mucha variabilidad, y esa variabilidad es una ventaja para describir dicho estado con la mayor completitud posible.
Si estudiamos los mecanismos que subyacen a la percepción gustativa, entonces puede que queramos caracterizar a un sujeto específico en relación con su experiencia subjetiva con las moléculas FTU y AB. Pero, antes de eso, podríamos (y deberíamos) estar interesados en una pregunta diferente: ¿a qué sabe la FTU? Para responder esta pregunta, necesitamos cambiar de perspectiva y acumular reportes de muchas personas distintas sobre sus experiencias con FTU, en vez de acumular muchos datos de una sola persona en relación con su experiencia con FTU. De hecho, vimos que un único reporte siempre fracasa en responder preguntas sobre el sabor de la FTU, justamente porque la molécula tiene distinto sabor para distintas personas. Únicamente investigando una enorme cantidad de reportes sobre la FTU podemos trascender el nivel de las anécdotas y aproximarnos a una descripción objetiva. De nuevo, una forma de entender este proceso es como la adopción de la perspectiva estadística respecto de la experiencia subjetiva, en otras palabras: se trata de poner la experiencia subjetiva misma dentro de la autocaja.15En la práctica, esto equivale a construir una autocaja enorme y poner dentro de ella a todas las personas que están teniendo esa experiencia subjetiva.
Consideremos una pregunta muy razonable, análoga a la que hicimos sobre el gusto de la FTU: ¿cómo se siente estar bajo los efectos de una droga psicodélica? O, con más generalidad, ¿cómo se siente estar bajo los efectos de distintas drogas psicoactivas? Siempre podemos recopilar información anecdótica entrevistando a usuarios de estas drogas (o probándolas nosotros mismos). Pero este no es el tipo de datos que nos proporcionan las autocajas: necesitamos más datos, los suficientes como para cubrir una porción razonable del espacio muestral. Por ejemplo, necesitamos una base de datos con reportes de experiencias de muchísimos usuarios distintos con una amplia variedad de drogas psicoactivas. Una posibilidad es disponer de esta información en forma de relatos sobre la experiencia, un oscuro subgénero literario conocido como trip report e inmortalizado por la pluma de Aldous Huxley en su libro Las puertas de la percepción, en el que describe su primera experiencia con medio gramo de mescalina durante un día primaveral de 1953.
De hecho, la base de datos que necesitamos existe desde el año 1995 y se llama Erowid.16Los relatos de experiencias en Erowid (www.erowid.org) son públicos, pero, al mismo tiempo, Fire y Earth (los seudónimos de los fundadores del sitio) pretenden ejercer un control estricto sobre su uso. Esto resulta en una situación paradójica: uno puede acceder a los datos, pero no utilizarlos sin el permiso de Fire y Earth. Como la jurisprudencia sobre copyright en internet los contradice, decidí ignorarlos y programar un algoritmo para recorrer la base de datos y bajar todos los reportes. Fire y Earth se defendieron bloqueando mi dirección de IP, y yo contraataqué pagando un servicio de VPN (Virtual Private Network) que me permitía adoptar direcciones de IP de cualquier lugar del planeta. Finalmente, logré bajar todos los reportes; con el tiempo, los analizamos, y cuando publicamos el primer artículo científico al respecto, recibimos un mail furioso de Fire y Earth reclamando su autoría en el trabajo. Propusimos una tregua y, a partir de ese momento, varios de nuestros trabajos tienen como coautores a Fire Erowid y Earth Erowid (incidentalmente, esto responde la pregunta de si es posible usar un seudónimo para publicar artículos científicos). En particular, las “bóvedas de experiencias” de Erowid contienen decenas de miles de relatos de experiencias con casi todas las drogas psicoactivas que se consumen de forma recreativa (lamentablemente, la calidad literaria de los reportes no está a la altura de Huxley). Cada reporte puede contener información adicional sobre el usuario (como edad y género) y también sobre la droga consumida (por ejemplo, dosis). Además, una buena parte de los reportes son sobre combinaciones de drogas (por ejemplo, marihuana combinada con LSD).
En el año 2016 empecé a plantearme muchas de las preguntas que terminaron dando origen a este libro. Principalmente, me preguntaba cuánto sabemos sobre la experiencia subjetiva durante distintos estados de conciencia y cuánto asumimos en base a anécdotas y memes culturales. La evidencia anecdótica es peligrosa, tal como ilustra el ejemplo de la FTU. Peor aún, los memes culturales instalados por los relatos históricos de científicos y escritores como Aldous Huxley o Albert Hofmann (quien sintetizó la LSD por primera vez en los años 40 y describió múltiples veces sus efectos) no solamente son evidencia de carácter anecdótico, sino que además pueden representar un sesgo importante para futuros reportes. Llegué a la conclusión de que no existía prácticamente literatura sobre el uso de grandes volúmenes de datos para caracterizar y clasificar los estados de conciencia inducidos por drogas psicoactivas. Incluso peor: no existía absolutamente ninguna investigación científica sobre la posible similitud entre las experiencias generadas por ciertas drogas y otro tipo de experiencias no farmacológicas, por ejemplo, el estado onírico alcanzado durante el sueño REM. Me resultó sorprendente encontrar en la literatura múltiples afirmaciones injustificadas sobre la similitud entre el estado psicodélico y los sueños; por ejemplo, en la descripción de los hongos psicodélicos del género Psilocybe realizada por Albert Hofmann y Richard Evans Schultes en el libro Plantas de los dioses se puede leer que “los hongos causan alucinaciones visuales y auditivas, transformando el estado onírico en la realidad”.
Junto con Camila Sanz investigamos estas preguntas en la que terminó siendo la primera tesis de mi laboratorio en la Universidad de Buenos Aires (Laboratorio de Conciencia, Cultura y Complejidad, conocido popularmente como COCUCO). Bajamos decenas de miles de reportes de experiencias subjetivas con drogas de Erowid y luego aplicamos técnicas de inteligencia artificial conocidas como NLP (Natural Language Processing, o procesamiento del lenguaje natural). Una primera parte del proceso consistió en transformar el texto de los relatos en datos numéricos, lo cual requiere examinar (entre otras cosas) el rol sintáctico de cada palabra en cada oración, para luego transformar cada palabra en su raíz y contar todas las inflexiones de una misma raíz como una única palabra (por ejemplo, “leo”, “leerás” y “leamos” son palabras que se convierten en una única raíz, “leer”).17Además, hay un proceso importante de censura sobre los datos: debido a que únicamente nos interesa la parte del relato que está relacionada con las experiencias subjetivas, removemos palabras que indiquen el nombre de la sustancia (y sus variaciones en la jerga callejera), el método de administración de la droga, etc. Una vez que transformamos el texto en una secuencia de símbolos que representan raíces únicas, contamos la frecuencia con la que cada raíz ocurre en cada documento, es decir, en cada conjunto total de relatos asociados a una droga determinada. Por ejemplo, para cada una de las drogas LSD, oxicodona y metilfenidato tendremos tres largas secuencias que representan la frecuencia con la que cada palabra del vocabulario aparece en los reportes de la droga correspondiente. Estas secuencias son tan largas como la cantidad de palabras que hay en el vocabulario (decenas de miles).
La intuición detrás de nuestra medida de distancia entre reportes es la siguiente: si los usuarios usaron las mismas palabras y con la misma frecuencia para describir sus experiencias, entonces es razonable inferir que estaban hablando de lo mismo. De lo contrario, suponemos que están relatando experiencias diferentes, y, por lo tanto, hay una distancia mayor entre estas. Lamentablemente, hay varios problemas con la implementación directa de esta intuición. Por ejemplo, las dos frases “margaritas, violetas y gardenias reposan en un jarrón con agua” y “el florero está repleto de distintos tipos de flores” no tienen ninguna palabra en común y, sin embargo, su significado es prácticamente idéntico. Otro problema es que lidiamos con un vocabulario con decenas de miles de palabras y la mayoría de esas palabras se usan muy pocas veces en los reportes, mientras que unas pocas palabras dominan el ranking de frecuencia de uso. Pero esas palabras que se usan poco pueden ser fundamentales a la hora de decidir si dos conjuntos de reportes están relatando experiencias similares.
La solución es aplicar un algoritmo que reduce el enorme vocabulario a un pequeño grupo de números que representan fielmente el contenido semántico de los reportes. En nuestro caso utilizamos un algoritmo conocido como análisis semántico latente, pero también podríamos haber aplicado un autocodificador: ambos son procedimientos válidos para representar un conjunto de datos complejos mediante pocas dimensiones de interés. La ventaja del análisis semántico latente sobre el autocodificador es que nos permite asignar más fácilmente un significado intuitivo a cada uno de los números (aunque, por otro lado, asignar ese significado no es necesario si solo nos interesa la distancia entre los reportes).
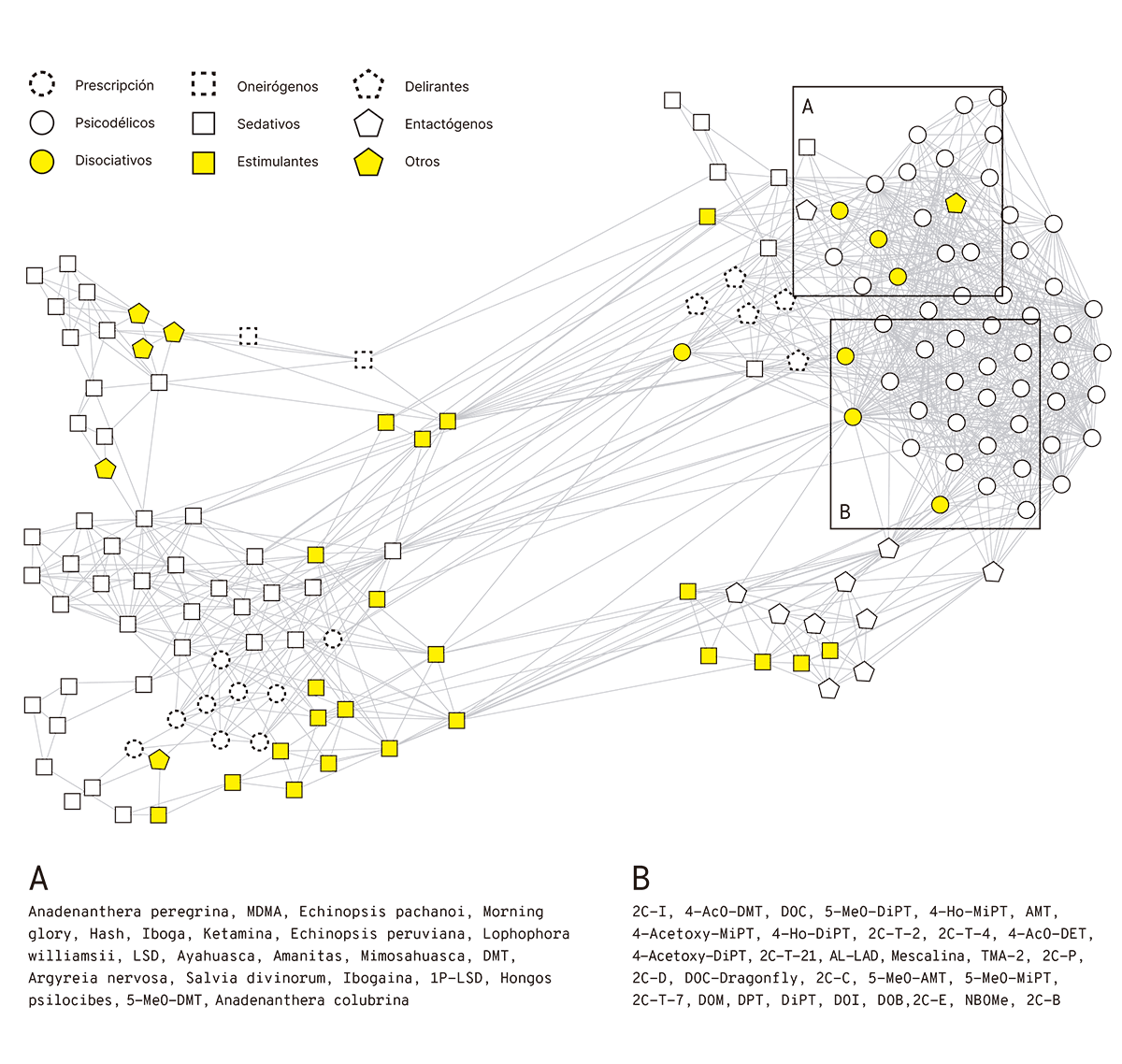
Siguiendo este procedimiento, logramos representar la base de datos de Erowid como una red donde cada punto representa los reportes de una droga psicoactiva en particular, y las conexiones aparecen únicamente si la distancia entre los reportes asociados es suficientemente baja. (Fig. 8.7)
Esta figura es un mapa de las experiencias subjetivas inducidas por cientos de drogas. Las familias a las que pertenece cada droga están indicadas mediante un código de colores y formas en los nodos. Las letras sirven para indicar distintas partes de la red. Por ejemplo, podemos ver que los círculos blancos se dividen en dos grupos densamente interconectados, A y B. Las drogas que pertenecen al grupo A se muestran en una nube de palabras al lado del grupo de nodos, e incluyen principalmente compuestos psicodélicos de origen vegetal: plantas, hongos y cactus consumidos por sus propiedades psicoactivas. Algunas de las drogas en este grupo no son estrictamente psicodélicos (por ejemplo, la Salvia divinorum o la Amanita muscaria), pero de todas formas son materiales vegetales capaces de introducir modificaciones muy profundas en el estado consciente de los usuarios. El grupo B también contiene drogas psicodélicas, pero en este caso la mayoría son sintéticas, muchas de ellas de difícil acceso y consumidas únicamente por connoisseurs de la psicodelia. Observamos una separación similar de las sustancias sedativas entre aquellas provenientes de agentes naturales y fármacos de prescripción. Cuando examinamos la diferencia entre los grupos A y B, encontramos que el grupo B contiene experiencias con mayor prevalencia de efectos denominados carga corporal (dolor de cabeza, hipertensión, bruxismo, taquicardia, etc.). Ambos grupos, por supuesto, tienen una alta prevalencia de contenido semántico que describe los efectos agudos de psicodélicos serotoninérgicos.
Imaginemos ahora una red como esta pero muchísimo más amplia, una red cuyos nodos no representan únicamente experiencias inducidas por fármacos. En esta red encontramos nodos asociados a sueños o a ciertos episodios psiquiátricos, pero también a eventos cotidianos como descansar después de un día de trabajo, salir con amigos a una fiesta, o aprobar un examen de la facultad. Cada vez que sumamos un punto nuevo a la red, calculamos automáticamente su distancia de todos los demás, y acomodamos los nodos de forma acorde. Cada agrupamiento tiene, a su vez, una estructura interna y jerárquica, como el caso de los nodos psicodélicos y sedativos, divididos en dos subgrupos cada uno (naturales vs. sintéticos). Este mapa representa un catálogo de la subjetividad humana, una taxonomía que nos permite explorar las relaciones mutuas entre distintas experiencias conscientes. Es importante notar que este mapa no tiene punto de referencia, porque se basa en la relación entre todos los pares de estados sin hacer referencia explícita a ninguno en particular. Por supuesto, una caracterización completa tendría que incluir además información exhaustiva sobre el autor de cada reporte, de forma tal que podamos entender sus posibles sesgos, idiosincrasia y hasta errores en la valoración de sus propios estados mentales conscientes.
Llevar adelante este proyecto en el lapso de décadas es perfectamente posible. Pensemos en la cantidad de información recopilada por Erowid en el transcurso de un cuarto de siglo, partiendo de un momento de la historia en el cual internet no era tan popular como ahora. Además, Erowid recopiló esta información de manera accidental, es decir, sin proponerse hacerlo en el contexto de un proyecto científico para estudiar la subjetividad humana.18Esto se nota en la pobre recopilación de metadatos sobre los sujetos: variables como edad, género, nacionalidad, y rasgos individuales, entre otras. Quizás sea hora de meter a la humanidad dentro de una gigantesca autocaja y construir un mapa más completo y detallado de la experiencia humana. Este sería un esfuerzo colectivo de autoentendimiento y autoexploración análogo a proyectos de ciencia ciudadana como iNaturalist,19iNaturalist (www.inaturalist.org) es un proyecto de ciencia colectiva en el cual los usuarios documentan la biodiversidad del planeta mediante fotos y distintos metadatos (principalmente su ubicación cuando tomaron la foto). que persiguen el mismo propósito, pero en cuanto al mundo natural e intersubjetivo. ¿Existe alguna diferencia fundamental entre ambos proyectos? Las diferencias aparentes son el resultado de un prejuicio profundamente arraigado en todos nosotros, un error que arrastramos contra toda razón, argumento y evidencia científica. Me refiero a la falsa creencia de que existe una línea nítida e importante que divide las experiencias causadas por factores externos (como viajar por el mundo) y por factores internos (como soñar, imaginar, alucinar, o consumir ciertas drogas), y que esa línea divisoria determina, además, el valor relativo que tienen ambos tipos de experiencias.

Mi interés por la relación entre sueños y psicodélicos empezó una oscura tarde de invierno de 2016, cuando fui al cine a ver El abrazo de la serpiente invitado por mi amigo, el filósofo Maximiliano Zeller. La película muestra dos historias paralelas separadas por tres décadas; en cada una, un explorador europeo recorre la profundidad del Amazonas colombiano en busca de una planta conocida como chakruna en el idioma nativo. Esta es la planta que en Occidente denominamos Psychotria viridis, y sus hojas aportan la molécula psicodélica N,N-dimetiltriptamina (DMT) a la cocción amazónica conocida como ayahuasca. La DMT es inactiva cuando se la consume oralmente, pero en la ayahuasca su combinación con la planta Banisteriopsis caapi hace que sus efectos se activen, lo que resulta en un brebaje que induce un profundo estado psicodélico al consumirse.
La motivación del personaje de la historia más vieja (basado en el explorador alemán Theodor Koch-Grünberg) es encontrar la chakruna para poder curar una enfermedad que lo consume lentamente. “Soñar no me da miedo, sino morir en este infierno”, le dice a Karamakate, un poblador indígena que lo guía a través de la jungla. El personaje que recorre el Amazonas treinta años después está basado en Richard Evans Schultes, el padre de la etnofarmacología moderna, y sus motivaciones para encontrar la chakura son mucho menos claras. Ya anciano, Karamakate lo cuestiona hasta recibir una enigmática respuesta: “Nunca he soñado, ni dormido ni despierto”. En sus conversaciones con Karamakate, ambos personajes usan la palabra “soñar” para referirse a los efectos de la ayahuasca.
Al parecer, Karamakate no conoce una palabra específica para referirse a los efectos de la ayahuasca, pero ¿por qué habría de hacerlo? Ni el inglés ni el castellano la tienen. Hablamos de viajes psicodélicos y de viajar bajo los efectos de una droga, porque esa es la analogía que elegimos para capturar la esencia del fenómeno (quizás porque los psicodélicos nos transportan desde un punto de partida hacia un punto de llegada a través de una multitud de nuevas experiencias, como en un viaje). Pero también podríamos decir que los psicodélicos hacen soñar, y entonces hablar de sueños y de soñar en vez de viajes y viajar.
El carácter anecdótico de una afirmación sobre una experiencia consciente es inversamente proporcional a la cantidad de personas que hacen esa afirmación. Siempre que tengamos suficientes datos, las mismas herramientas que usamos para construir un mapa de experiencias farmacológicas pueden aplicarse para determinar la distancia entre cada una de ellas y el estado onírico. La pieza faltante es la información dada por una autocaja con una humanidad que sueña en su interior. Para aproximar esa información, recurrimos a otra base de datos generada por usuarios de internet, en este caso, usuarios que sueñan: Dreamjournal.20
Antes de relacionar sueños y psicodélicos, es un buen momento para discutir lo que sí sabemos sobre cada uno por separado. La mayoría de las drogas psicoactivas ejercen su efecto imitando la acción de distintos neurotransmisores, moléculas que se encuentran naturalmente en el cerebro humano y juegan un papel fundamental en la comunicación entre neuronas. Por ejemplo, tanto el alcohol como los sedativos conocidos como benzodiacepinas (por ejemplo, el clonazepam) imitan el efecto de un neurotransmisor llamado ácido γ-aminobutírico, cuyo efecto es inhibir la actividad neuronal. La anfetamina activa receptores que son normalmente el objetivo de la dopamina, y, por lo tanto, incrementa exageradamente la actividad neuronal en regiones cerebrales moduladas por este neurotransmisor, en particular aquellas asociadas al sistema de recompensa en el núcleo accumbens (lo cual explica el carácter adictivo de la anfetamina y de otras drogas que interfieren con el sistema dopaminérgico, por ejemplo, la cocaína). Todas las drogas psicodélicas actúan imitando el efecto de la serotonina en un receptor conocido como 2A. Cuando un compuesto psicodélico se une al receptor de serotonina tipo 2A inicia una cascada de eventos intracelulares que cambia el patrón de comportamiento de los circuitos neuronales locales, lo que, con el tiempo, escala a la actividad global del cerebro en regiones fronto-parietales (las mismas que las del espacio global de trabajo) y resulta en modificaciones muy profundas e idiosincráticas de la experiencia subjetiva del usuario. Estos cambios incluyen modificaciones en la percepción visual,21Los cambios visuales inducidos por los psicodélicos son más similares a filtros aplicados sobre la percepción que a alucinaciones propiamente dichas. Estos filtros se corresponden con cambios en los colores, texturas y formas, pero no inducen imágenes visuales de objetos complejos. Los efectos visuales inducidos por los psicodélicos se manifiestan incluso con los ojos cerrados, a veces en la forma de coloridos patrones geométricos que reflejan la información de otros sentidos (principalmente, los sonidos y la música). fusión de los sentidos (sinestesia), mayor volatilidad emocional, interferencia con ciertas funciones cognitivas, y una profunda reconfiguración de los límites corporales percibidos por el usuario (por ejemplo, la sensación de que objetos externos pasan a formar parte de uno mismo). Hasta hoy, somos incapaces de explicar por qué la unión de una molécula psicodélica con el receptor 2A desencadena todos estos efectos.
Nuestros sueños parecen ser, en varios sentidos, muy diferentes. Al soñar, conjuramos mundos imaginarios complejos y convincentes, incluso cuando dentro de esos mundos suceden cosas que desafían la lógica y el sentido común. La capacidad para examinar y evaluar el funcionamiento de nuestra propia mente (metacognición) está comprometida durante los sueños, pero no durante los efectos agudos de un viaje psicodélico (casi siempre, el usuario tiene plena conciencia de estar bajo el efecto de una droga). Encontramos similitudes en la intensidad del contenido emocional presente en ambas experiencias, y también en las distorsiones de las fronteras que delimitan nuestro cuerpo y nuestro punto de vista en primera persona. Los sueños nos encuentran a veces observando eventos en los que no estamos presentes, como puntos de vista sin identidad flotando en el espacio. En algunas ocasiones, nosotros mismos estamos presentes en las acciones que observamos desde la tercera persona; en otras, perdemos nuestra identidad e incluso la noción de nuestra existencia individual.
Tanto la experiencia onírica como el estado psicodélico infunden una sensación de irrealidad, al distorsionar nuestros sentidos lo suficiente para reducir nuestra familiaridad, pero no tanto como para hacernos dudar de que se trate, efectivamente, de nuestros propios sentidos. Esta sensación de ligera extrañeza está capturada magistralmente en dos películas dirigidas por Richard Linklater, ambas filmadas usando una técnica conocida como rotoscopia, que consiste en superponer dibujos sobre acción en vivo filmada con verdaderos actores. Es interesante notar que una de estas películas se basa en el estado onírico (Waking Life, conocida en castellano como Despertando a la vida), mientras que la otra trata sobre los efectos de una potente droga psicodélica (A Scanner Darkly, traducida como Una mirada en la oscuridad). Estas películas capturan una tenue sensación presente en ambas experiencias, una sensación que se disipa por completo en el instante en que cruzamos el umbral hacia la vigilia.
Volvamos, entonces, a los resultados de nuestra investigación, que confirmaron de forma espectacular estas observaciones anecdóticas sobre la similitud entre los sueños y el estado psicodélico. El análisis computacional de los relatos nos permitió ordenar 165 drogas psicoactivas de acuerdo a la similitud de sus efectos con experiencias oníricas de distinto nivel de lucidez. Las cinco drogas que presentaron la mayor similitud con sueños de alta lucidez fueron LSD (psicodélico), Lophophora williamsii (un cacto conocido como peyote que contiene mescalina, un psicodélico), daturas, hongos psilocibes (un género de hongos que contienen psilocibina, un compuesto psicodélico), y cannabis. Además, encontramos que la mitad de las veinte drogas con mayor similitud con los sueños eran compuestos psicodélicos; en cambio, no encontramos ningún psicodélico dentro de las veinte drogas con menor similitud con los sueños.
Notamos que la lista incluye las daturas y el cannabis. El cannabis es una de las drogas más familiares de Occidente y, por lo tanto, no necesita presentación. Pero ¿qué son las daturas y por qué aparecen en una lista de las drogas más oníricas? Se trata de varias plantas dentro de un mismo género botánico; por ejemplo, Datura ferox, Datura metel y Datura stramonium. Estas plantas contienen moléculas conocidas como alcaloides tropanos; más precisamente, atropina, escopolamina e hiosciamina. Consumir estos compuestos resulta en un profundo estado alucinatorio similar a un delirio (por eso su denominación de agentes delirantes o deliriógenos). Alguien que haya consumido estas drogas dará señales de percibir un entorno dominado por alucinaciones complejas e interactivas (como personas y animales). Además, generalmente será incapaz de detectar la naturaleza irreal de estas, hasta el punto de desconocer estar bajo los efectos de una droga. Si para algún lector esto llegase a parecer atractivo o (como mínimo) interesante, es muy importante remarcar que las experiencias inducidas por estas plantas y sus alcaloides son universalmente calificadas como horrendas. Los alcaloides tropanos son drogas muy tóxicas que afectan distintas funciones autónomas del organismo, tales como la función intestinal, la sudoración, y la micción; además, pueden afectar por días y hasta semanas la capacidad para enfocar imágenes en la retina, causando pérdida de la visión. La principal similitud entre el estado onírico y el efecto de los agentes delirantes es la pérdida de lucidez y la dificultad para recordar los eventos ocurridos durante la experiencia.
Cuando listamos las drogas cuyos efectos presentan la mayor similitud respecto de experiencias oníricas de baja lucidez, encontramos que los agentes delirantes son considerablemente más prevalentes que en el caso de sueños de alta lucidez. Las cinco drogas más oníricas (de baja lucidez) pasan a ser las daturas, la LSD, las brugmansias, el cacto Lophophora williamsii, y el cannabis. Ahora las plantas deliriógenas del género Datura se encuentran en el primer lugar, y otro género de plantas con las mismas propiedades aparece en el ranking: se trata de las Brugmansias (conocidas en Argentina como floripondio), plantas muy tóxicas capaces de inducir un estado de conciencia extremadamente alterado y fragmentado mediante la acción de alcaloides tropanos. Esta dependencia entre el nivel de lucidez y las cinco drogas con mayor similitud con el estado onírico sugiere que el método aplicado es suficientemente sutil como para detectar la pérdida de lucidez que caracteriza a los agentes delirantes respecto de los psicodélicos.
Estos resultados se basan únicamente en el análisis de relatos en primera persona, pero son consistentes con mucho de lo que sabemos sobre la neurofisiología y la neuroquímica del sueño REM; en otras palabras, una verdadera autocaja podría relevar variables biológicas y mostrar un estrecha relación con los resultados del análisis computacional de los relatos. Sabemos que el sueño REM reduce el flujo sanguíneo (un indicador de menor actividad neuronal) en regiones frontales y posteriores del cerebro, regiones que se vinculan con la capacidad para la metacognición; por otro lado, incrementa el flujo sanguíneo (un indicador de mayor actividad neuronal) en la amígdala y la corteza cingulada anterior, regiones que típicamente responden a estímulos con una fuerte carga emotiva. Los resultados de experimentos de neuroimágenes sobre el estado inducido por el compuesto psicodélico psilocibina son convergentes con este patrón de cambios. Hoy sería difícil por objeciones éticas,22Aunque es justo preguntarnos por qué, dado que la LSD es una de las drogas más seguras que conocemos. pero en los años 50 se investigó el efecto de inyectar LSD a individuos durante el sueño, y se descubrió un aumento considerable del tiempo total que los sujetos pasaban en sueño REM. Es decir, las drogas psicodélicas desencadenan un estado similar al ensueño durante la vigilia y precipitan episodios de sueños propiamente dichos (sueño REM) cuando son administrados a sujetos mientras duermen.
Siempre que tengamos suficientes relatos en primera persona podremos repetir este análisis para evaluar aseveraciones anecdóticas sobre cómo se sienten distintos estados de conciencia. Dentro de las muchas comparaciones de este estilo que se encuentran en tradiciones orales y en la literatura, hay una que es tan interesante como controversial: la comparación entre morir y el estado inducido por psicodélicos.
Cerca de finalizar uno de los primeros registros televisivos de una experiencia inducida por LSD, la cámara enfoca a un muy anciano Gerald Heard, quien declara, con una enigmática actitud risueña: “Una o dos personas me lo han dicho, y yo también me lo he dicho a mí mismo: así es como va a ser morir. ¡Y qué divertido que va a ser!”. Pero ¿qué sentido puede tener una afirmación semejante? ¿No es necesario haber experimentado el proceso de morir para afirmar que algo se le parece?
Ciertos compuestos psicodélicos son ocasionalmente vistos como herramientas para establecer un canal de comunicación entre los vivos y los muertos, un canal que se asegura haciendo atravesar al usuario por una experiencia de muerte y resurrección. Tanto el peyote como la ayahuasca son parte de rituales cuyo fin es contactar a los muertos; de hecho, la palabra “ayahuasca” se traduce del idioma quechua como “la liana de los muertos”.23 Pero la relación entre los psicodélicos (principalmente la DMT, el principio activo de la ayahuasca) y el proceso de muerte-resurrección no es más que folklore anecdótico, alimentado originalmente por una extraña reinterpretación de El libro tibetano de los muertos por parte de Timothy Leary, Richard Alpert y Ralph Metzner, luego revalidada por Rick Strassman en su libro DMT: La molécula del espíritu.24La hipotética relación entre DMT, muerte y resurrección forma crecientemente parte de la cultura popular. Un ejemplo es la película Enter the Void, dirigida por Gaspar Noé. La idea detrás de estas especulaciones es que los psicodélicos son capaces de imitar la fenomenología (el cómo se siente) del ciclo de muerte y resurrección. Ninguna persona racional afirma que los psicodélicos realmente llevan al usuario a través de ese ciclo, sino que inducen una experiencia que se siente como si lo hicieran.
Por otra parte, ¿sabemos algo sobre cómo se siente morir? Desde los años 70 en adelante, algunos investigadores han notado un fenómeno que se repite con bastante frecuencia. Una persona sobrevive a un contacto cercano con la muerte, por ejemplo, debido a un accidente o como consecuencia de una intervención médica, y luego relata haber transitado un estado alterado de conciencia con ciertas características típicas: disociación entre el punto de vista subjetivo y el cuerpo (fenómeno conocido como experiencia extracorpórea), sensaciones de profundo contento y felicidad, y la sensación de desplazarse por una especie de túnel hacia una luz, donde se manifiesta la presencia de un umbral irreversible. Este tipo de experiencias se conocen como cercanas a la muerte, y son un imán tanto para científicos serios como para charlatanes y estafadores. Entre los científicos serios, encontramos a Bruce Greyson, quien dedicó su vida a explorar y caracterizar reportes de experiencias cercanas a la muerte. Para esto, Greyson desarrolló una escala psicométrica que permite puntuar la intensidad con la que se manifiestan en un relato los rasgos típicos de las experiencias cercanas a la muerte. Además, usó esta escala para demostrar que los contenidos de estas experiencias parecen ser universales (en el sentido de no depender del contexto cultural de quien las reporta) y presentar algunas sutiles variaciones de acuerdo a la causa del suceso (es decir, el factor al cual se atribuye la cercanía con la muerte). Greyson también trabajó para desmitificar la posible relación entre estas alteraciones de la conciencia y la proximidad real con la muerte, poniendo en evidencia relatos de experiencias cercanas a la muerte en individuos que no corrieron en ningún momento riesgo vital. A pesar de lo que muchos querrían escuchar, sabemos suficiente sobre las experiencias cercanas a la muerte como para descartar que representen una prueba de que hay vida después de la muerte, aunque eso no significa que sean fenómenos poco interesantes desde el punto de vista científico.
Mi interés en las experiencias cercanas a la muerte surgió, precisamente, de las comparaciones anecdóticas entre el estado psicodélico y el proceso de morir. De la misma forma en que utilizamos una gran cantidad de datos para estudiar la relación entre la experiencia onírica y el estado psicodélico, decidí que también podíamos poner a prueba la hipotética relación entre morir y el estado psicodélico. Para eso, establecimos una colaboración con Bruce Greyson, quien amablemente nos suministró cientos de relatos retrospectivos de experiencias cercanas a la muerte, cada uno de ellos con un puntaje de acuerdo a su escala psicométrica y también con datos sobre la causa sospechada de la experiencia.
Si bien los psicodélicos resultaron en relatos similares a los de experiencias cercanas a la muerte, fue otra la droga que los reprodujo con la mayor similitud: la ketamina. La ketamina es una de las drogas más fascinantes que existen, si no la más fascinante de todas (al menos para un investigador interesado en la conciencia). Es también una de las más versátiles, con usos reconocidos como droga anestésica (y no únicamente para caballos, como se suele creer), como agente antidepresivo de acción rápida, con potenciales usos contra adicciones, y como medio para reducir la ansiedad ante el fin de la vida en pacientes terminales. La ketamina actúa bloqueando la acción del glutamato, el principal neurotransmisor excitatorio del cerebro, y tiene profundos efectos disociativos. El término “disociación” se usa en distintos contextos con distintos significados, pero en este caso significa simplemente que ciertos procesos mentales que siempre van de la mano (por ejemplo, dolor y sufrimiento) dejan de hacerlo. En dosis moderadas, la disociación inducida por la ketamina puede resultar en experiencias de profunda despersonalización (disociación entre el usuario y su identidad personal) y desrealización (disociación entre la realidad y la experiencia vivida);25La despersonalización y la desrealización son posibles síntomas de esquizofrenia, y por lo tanto, la ketamina agrega a su larga lista de usos el de psicotomimético, es decir, un agente químico capaz de inducir un estado transitorio semejante a la psicosis. en otras palabras, el usuario puede perder la capacidad de atribuir su identidad al pasado “yo” que recuerda en su memoria, y también de interpretar la información proveniente de los sentidos como la representación de un mundo externo real. En este estado, el usuario de ketamina puede perder la noción del vínculo que existe entre su pasado y su estado actual (“¿cómo llegué hasta este momento?”), al mismo tiempo que todo el mundo que lo rodea se le aparece como una sofisticada puesta en escena.
En dosis más altas, la ketamina gradualmente reduce el ancho de banda de los sentidos y ralentiza el flujo de los pensamientos. A medida que se bloquea la acción excitatoria del glutamato, la información encuentra más obstáculos para fluir entre dos puntos cualesquiera del cerebro. La percepción auditiva se va reduciendo hasta que tan solo se puede escuchar un pequeño fragmento de sonido, como si viniese desde un lugar muy lejano; por otra parte, la percepción visual se fragmenta en mosaicos irregulares hasta finalmente apagarse por completo. Llegado este punto, la disociación es total: el usuario se encuentra aislado del mundo externo por la acción de la ketamina y es incapaz tanto de percibir el mundo como de mover su propio cuerpo, aunque al mismo tiempo mantiene la conciencia. Este es el estado conocido como K-hole, y si bien suena a una experiencia horrible, muchos reportes de K-holes están marcados por una fuerte sensación de felicidad y bienestar. De hecho, estos reportes son notablemente similares a los que registran individuos luego de experiencias cercanas a la muerte, incluyendo la sensación de abandonar el cuerpo y flotar en el espacio dentro de una suerte de tubo hacia un umbral muy luminoso.
La similitud entre relatos de K-holes y relatos de experiencias cercanas a la muerte ya era conocida antes de nuestro estudio (aunque podemos decir que nosotros fuimos los primeros en publicar evidencia cuantitativa que apoyara esa relación). Por ejemplo, el psicólogo Timothy Leary afirmó que el consumo de ketamina es un “experimento de muerte voluntaria”. Algunos autores (por ejemplo, el psiquiatra Karl Jansen) han llegado a especular que en momentos críticos el cerebro segrega de forma natural compuestos farmacológicamente similares a la ketamina, compuestos que preservan la vida de las neuronas ante el trauma causado por la falta de oxígeno. Si bien existe alguna evidencia de que la ketamina puede tener efectos neuroprotectores, no se ha podido demostrar de forma concluyente (y tampoco se han encontrado los compuestos naturales propuestos por Jansen). Esto no significa que la ketamina no induzca un estado similar al de una experiencia cercana a la muerte, pero, si lo hace, seguramente sea por medio de un mecanismo neurobiológico diferente.

Estos ejemplos nos permiten vislumbrar un camino para dotar de significado al insólito caudal de datos recopilado por las omnicajas. El desafío es obtener una cantidad manejable de números que permitan introducir una medida de distancia entre experiencias subjetivas. A medida que estudiamos más y más experiencias, empieza a formarse una red de complejidad creciente cuyos nodos son experiencias conscientes, y las conexiones entre estos indican cuán diferentes son las experiencias correspondientes. En algún lugar de esta red, encontramos nodos asociados a experiencias durante experimentos científicos sobre la conciencia; en otras partes, nodos que hacen referencia a experiencias oníricas o al efecto de distintas drogas. Pero en ningún sitio encontraremos un nodo especial que sirva como punto de referencia para comparar todos los demás: aquello que llamamos vigilia ordinaria será un nodo más, en pie de igualdad con todos los otros.
Pero incluso esta visión es limitada: en realidad, tenemos que imaginar múltiples redes, una por cada fuente distinta de datos que registramos en nuestro experimento. Medir la actividad cerebral de los sujetos nos permite introducir otra distancia entre experiencias subjetivas, una distancia basada en mediciones objetivas sobre el cerebro, es decir, una medida de distancia entre nudos. ¿Cuál es la relación entre la distancia basada en actividad cerebral y aquella basada en variables comportamentales, o en relatos en primera persona? A medida que nos movemos de forma continua en uno de los espacios, ¿nos movemos de forma continua en todos los demás? ¿Existen múltiples estados cerebrales distintos asociados con la misma experiencia consciente? ¿Y al revés? ¿Cuál es la transformación que vincula estados cerebrales con reportes de experiencias subjetivas, y viceversa?
Estas preguntas dependen de registrar la actividad cerebral humana durante distintas experiencias subjetivas, lo cual es muy costoso, tanto en tiempo como en dinero. Así como nuestro entendimiento de la conciencia depende de compilar enormes cantidades de reportes sobre distintas experiencias subjetivas, también es necesario construir bases de datos más y más exhaustivas sobre la actividad cerebral vinculada a esos reportes. Este es un proceso largo, tedioso, y posiblemente multigeneracional.26¿Y por qué no habría de serlo? Asumimos con naturalidad desafíos como la secuenciación del genoma humano o el descubrimiento del bosón de Higgs, ambos proyectos científicos costosísimos que requieren la acción coordinada de múltiples centros de investigación. ¿Por qué la tarea de descifrar la conciencia humana debería recaer sobre unos pocos laboratorios aislados y mal financiados? Y ya que estamos en esto, ¿por qué muchos esperan resultados pasados unos pocos años, en ausencia de los cuales no dudan en declarar que el problema de la conciencia es irresoluble? ¿Y qué nos dice sobre el ser humano la suposición de que entender su propia conciencia debe requerir menos recursos que resolver muchísimos otros problemas de las ciencias biológicas y físicas, aun cuando esos otros problemas no tendrían siquiera sentido fuera del contexto de la experiencia subjetiva humana? En nuestro laboratorio empezamos a avanzar tímidamente sobre estos problemas; por ejemplo, con Carla Pallavicini y Yonatan Sanz Perl buscamos formas de introducir distintas medidas de distancia entre estados de conciencia. Investigando registros de magnetoencefalografía, demostramos que los estados inducidos por distintos psicodélicos (LSD, psilocibina) son altamente similares entre sí, pero que difieren sustancialmente de aquellos obtenidos bajo los efectos de la ketamina. También mostramos que existen muchas formas distintas de estar inconsciente: la anestesia general, el sueño profundo y el estado vegetativo tienen algunos rasgos en común, pero difieren en muchos otros.27Esto responde la pregunta de si distintos estados cerebrales pueden estar asociados a una misma experiencia subjetiva: sí, siempre y cuando aceptemos que distintos estados de inconciencia están asociados a la misma experiencia subjetiva (es decir, a la ausencia de experiencia subjetiva). A pesar de estos avances, estamos severamente limitados por la escasa cantidad de datos de neuroimágenes disponibles en la actualidad. Cada nuevo experimento es una contribución significativa: representa un nodo más en la red, un paso hacia adelante en el programa de explorar exhaustivamente el amplio rango de experiencias disponibles para el ser humano.
Vamos a ilustrar estas ideas con un ejemplo concreto, un caso particular que no se encuentra limitado por la necesidad de realizar nuevos experimentos de neuroimágenes. También es un gran ejemplo de por qué considero invaluable la investigación farmacológica sobre la conciencia. Supongamos que disponemos de relatos acerca de las experiencias subjetivas causadas por muchas moléculas psicodélicas diferentes. Si bien cada una de estas moléculas presenta actividad en el receptor de serotonina 2A (como es el caso para todos los psicodélicos), encontramos diferencias sustanciales en los relatos correspondientes a distintas drogas. Algunas moléculas parecen inducir experiencias muy visuales, mientras que otras se inclinan hacia lo auditivo o lo táctil; algunas afectan casi selectivamente la conciencia y sus contenidos, pero otras tienen desagradables consecuencias físicas tales como taquicardia o dolor de cabeza; algunas inducen estados pacíficos y contemplativos, mientras que otras tienen una tendencia a desencadenar estados de pánico y confusión.
¿Por qué distintas moléculas psicodélicas tienen distintos efectos subjetivos? Una respuesta posible es que distintas moléculas generan distintas experiencias porque sus efectos sobre la actividad cerebral son, a su vez, distintos. Esta respuesta es correcta (¿cómo podría no serlo?) aunque no demasiado informativa. Quisiéramos entender precisamente qué aspectos de la actividad neuronal se corresponden con las peculiaridades del estado inducido por cada droga, pero para eso necesitaríamos registros de neuroimágenes obtenidas bajo los efectos de cada una de las drogas. Pero esto es imposible, no solo por limitaciones económicas, sino también éticas: algunas de las drogas que queremos investigar son capaces de inducir experiencias largas, agotadoras y potencialmente terroríficas, con 48 horas de duración o más. Por suerte, disponemos de relatos de los efectos de estas drogas gracias a los usuarios de Erowid, quienes están dispuestos a probar prácticamente cualquier compuesto químico y escribir al respecto, incluso en casos en que es muy poco recomendable hacerlo (así que, ya existiendo esos datos, ¿por qué desaprovecharlos?). Sería muy diferente inducir estas experiencias subjetivas en un laboratorio, algo que está y estará permanentemente fuera de nuestro alcance, al menos mientras la investigación científica adhiera a ciertos estándares éticos básicos.
Aquí yace el valor de estudiar experiencias inducidas por moléculas.28No me refiero únicamente a experiencias inducidas por drogas psicoactivas, sino también a la percepción olfativa, otra de las líneas de investigación que perseguimos en el laboratorio. Las moléculas son objetos que se pueden comparar en términos de su estructura física (es decir, su estructura molecular) y también en términos de la interacción de dicha estructura con los distintos receptores que encontramos en el cerebro. La idea de que podemos comparar moléculas en términos de su estructura física es intuitiva, de hecho, ya lo hicimos hace dos capítulos cuando escribimos las fórmulas de la FTU y la AB y las comparamos visualmente, incluso sin conocer su significado exacto.
Y si bien existen dificultades insuperables para introducir una distancia entre la actividad neuronal asociada a los efectos de cada droga psicodélica, podemos aproximarnos cuantificando cómo cada molécula interactúa con los receptores que se encuentran en las neuronas. Conocemos con qué facilidad cada una de las moléculas se une a los distintos receptores, y también cuál es la consecuencia de esta unión en términos de la actividad de la neurona. Este es un paso anterior a los cambios que se generan en el cerebro por haber consumido la droga. Podemos pensar en una jerarquía de tres distancias posibles entre moléculas, cada una de ellas más específica, pero al mismo tiempo más difícil de obtener.
Primer nivel: ¿qué tanto se parecen las moléculas estructuralmente? El problema con esta medida es que la acción en el cerebro no está determinada únicamente por la estructura de la molécula, sino también por la interacción entre esa estructura y la de los receptores (de la misma forma que el acto de abrir una cerradura está simultáneamente determinado por la forma de la llave y la forma de la cerradura). Eso quiere decir que dos moléculas muy similares pueden tener efectos muy diferentes.29Un ejemplo notable es el caso de la lisurida (un medicamento que se utiliza, entre otras cosas, para el tratamiento de migrañas) y la LSD (una droga psicodélica).
Segundo nivel: ¿cómo se unen las moléculas a los receptores? Si conocemos con detalle la unión entre la molécula y los receptores, podemos hacernos una idea de lo que va a suceder a partir de ese momento, de la misma forma en que entendemos la cascada que se produce después de empujar la primera pieza de un dominó. Pero este conocimiento es limitado, porque los detalles de la actividad neuronal dependerán de cada circunstancia particular así como de las expectativas del usuario, su historia personal y otros rasgos individuales.
Tercer nivel: ¿cómo es la actividad neuronal causada por la droga en cierto individuo? Para esto, deberíamos realizar experimentos de neuroimágenes en sujetos bajo los efectos de distintas drogas. Nuestro conocimiento sobre este nivel se encuentra impedido por consideraciones éticas para una gran cantidad de moléculas psicodélicas, aunque en el futuro quizás podamos aproximarlo mediante simulaciones computacionales.30Junto con colegas de la Universidad de Valparaíso realizamos modelos computacionales capaces de imitar la activación causada por la LSD en todo el cerebro.
Junto con Federico Zamberlan (otro de los primeros doctorandos de mi laboratorio), exploramos la relación que existe entre los dos primeros niveles y las experiencias subjetivas narradas por usuarios de Erowid para un amplio conjunto de moléculas psicodélicas. Las moléculas que investigamos fueron las siguientes: mescalina, 2C-B, 2C-E, 2C-T-2, DOB, DOI, DOM, TMA-2, MDA, MDMA, DMT, 5-MeO-DMT, 5-MeO-MiPT, DiPT, 5-MeO-DiPT, DPT y LSD. Es poco probable que el lector reconozca muchas de las moléculas en esta lista (las más conocidas son mescalina, DMT, MDMA y LSD). La mayoría de las otras moléculas fueron sintetizadas por primera vez por el mítico Alexander Shulgin, un químico que dedicó varias décadas de su vida a explorar las posibles variantes de moléculas psicodélicas conocidas (principalmente la mescalina) para luego consumirlas y documentar sus efectos.
Encontramos que las moléculas más similares en el sentido estructural resultan en experiencias más similares en cuanto al análisis de los reportes subjetivos. Pero todavía más cercano es el vínculo con la similitud de la acción sobre los receptores neuronales. Y predecimos una relación aún más cercana con la similitud de la actividad cerebral asociada a las drogas consumidas (si pudiésemos medirlo).
Únicamente partiendo de las experiencias subjetivas y de la forma en que cada molécula se une a distintos receptores, pudimos trazar perfiles asociados a cada experiencia y vincular las distintas dimensiones de estos perfiles con receptores específicos. Podemos imaginar un autocodificador que reduce miles y miles de narrativas a unos pocos números, que, descubrimos, se asocian a las características de un viaje psicodélico (por ejemplo, cambios en la percepción visual, auditiva, o efectos físicos tales como taquicardia y dolor de cabeza). Estos números, a su vez, se asocian a la activación de receptores específicos: activar el receptor 2A resulta en profundos cambios en la percepción visual, mientras que activar receptores adrenérgicos resulta en tensión muscular y otros efectos físicos desagradables. Desde esta perspectiva, el trabajo de Alexander Shulgin se parece al de un organista que aprende las consecuencias de presionar distintas teclas de su instrumento, y luego las combina para generar experiencias subjetivas con características específicas. Solo que en este caso, las teclas se corresponden con variaciones químicas sobre una estructura de base.31Esta analogía, si bien es muy poética, es incorrecta. En un órgano (u otros instrumentos musicales), si tocamos dos notas, sus sonidos se superponen, de forma tal que el resultado es la suma de ambas. El cerebro es mucho más complicado: si activar el receptor A se asocia con un determinado efecto, y activar el receptor B se asocia con otro efecto, activar ambos simultáneamente no siempre se asocia con la ocurrencia simultánea de ambos efectos.
Lamentablemente, el mundo científico todavía no parece estar listo para explorar de forma sistemática el rango de experiencias conscientes que surgen de manipulaciones farmacológicas. Shulgin sabía que el uso más valioso de su trabajo sería en la exploración de la conciencia y decía construir herramientas para este fin. Tiene sentido: conocer la conciencia humana ordinaria (aun si existiese tal cosa) es un objetivo limitado, tan limitado como la cantidad de estados de conciencia que abarca esta definición. ¿Cómo podemos hacer, entonces, para recorrer los estados que quedan fuera de la “conciencia ordinaria”? Diseñamos vehículos (moléculas) que nos transportan a nuevos lugares. Los frutos de la ingeniería química de la conciencia pueden ser (y han sido) utilizados y abusados fuera de contexto, pero esto no quita mérito a su uso científico, de la misma forma en que la existencia de morfinómanos no impide que la morfina sea utilizada por sus extraordinarias cualidades anestésicas.

Hasta el día de hoy, el esfuerzo sigue puesto en entender la conciencia humana como si hubiese una sola, incluso una única conciencia para una misma persona a lo largo del tiempo. Estos esfuerzos están enfocados en experimentos que controlan con extremo detalle la presentación de estímulos sensoriales a los sujetos, pero que también regulan con precisión la forma en que los sujetos pueden reportar los contenidos de su experiencia. El instinto básico del científico es limitar y simplificar para poder llegar a conclusiones de validez universal. Pero quizás se haya limitado y simplificado demasiado en el estudio de la conciencia. Si decidimos abandonar esta perspectiva y enfocarnos en los detalles, incluso el más simple experimento puede desbordarnos de datos útiles para entender la conciencia, un caudal que únicamente una autocaja es capaz de ordenar y simplificar. Los ejemplos que visitamos en este capítulo contribuyen a deficcionalizar las autocajas. Contamos al día de hoy con suficientes datos para caracterizar ciertos estados mentales, no a nivel de únicos sujetos, sino de manera colectiva. Y si bien estamos aún lejos de un conocimiento teórico que nos permita comprimir estos datos en una elegante serie de axiomas, tampoco lo necesitamos para ponernos a trabajar. Contamos con procedimientos automáticos para reducir datos complejos a secuencias numéricas que, a su vez, nos permiten entender qué tan similares son ciertos pares de experiencias conscientes y sus sustratos cerebrales. Armados con una idea de distancia, podemos construir mapas que nos orienten en la búsqueda del conocimiento teórico, un trabajo exploratorio que me resulta increíblemente emocionante, principalmente porque se encuentra casi por completo en el futuro.
¿Es suficiente esta aproximación basada en recopilar enormes cantidades de datos para explorar la variedad de la conciencia humana y sus estados cerebrales subyacentes? Un aspecto fundamental de todo desarrollo teórico es partir de una base conceptual adecuada; por ejemplo, la química moderna no existiría sin conceptos como “átomos”, “moléculas” y “orbitales”. Estos conceptos no son palabras vacías (aunque su contenido pueda expresarse en palabras), sino que refieren a fenómenos que tienen poder explicativo y que requieren, a su vez, una explicación. Entonces, podemos preguntarnos, ¿estamos partiendo de una base conceptual adecuada para explicar la conciencia? ¿Son correctos los conceptos que utilizamos para referirnos a aquello que queremos explicar? Este punto puede resultar engañoso, porque en el caso de la mente y la conciencia, introdujimos conceptos mucho antes de embarcarnos en su estudio científico. Los introdujimos porque son útiles para comunicar nuestros propios estados internos y nuestras facultades cognitivas, pero eso no significa que sean cimientos sólidos para construir una teoría científica. Usamos términos como “atención”, “memoria”, “percepción” e incluso “conciencia”, pero ¿existen realmente fenómenos asociados a estos conceptos? ¿O es necesario barajar y dar de nuevo, pero esta vez informándonos mejor sobre aquello que sabemos del cerebro?
Estas son algunas de las preguntas que intentaremos responder en el próximo capítulo. Nuevamente, el lenguaje es enormemente informativo para estudiar la experiencia subjetiva, pero al mismo tiempo es un limitante: usamos las palabras de las que disponemos, ignorando si son suficientemente específicas, o incluso si denotan cosas que siquiera existen.
Estos nuevos interrogantes no son una consecuencia de las limitaciones de las omnicajas: todos ellos pueden ser respondidos mediante los datos que ellas proporcionan. No podría ser de otra manera, porque no existe nada que necesitemos saber sobre la conciencia humana que se escape a las omnicajas. Solo tenemos que saber dónde buscar.